defforward(self, x): x = self.activate(self.linear1(x)) x = self.activate(self.linear2(x)) # 计算y_hat时需要使用sigmoid,防止对数取到0. x = self.sigmoid(self.linear3(x)) return x
model = Model()
8 Dataset and DataLoader
Termininology: Epoch, Batch-Size, Iterations
1 2 3 4
# Training cycle for epoch inrange(training_epochs) #Loop over all batches for i inrange(total_batch):
Definition:Epoch
One forward pass and one backward pass of all the training examples.
Definition:Batch-Size
The number of training examples in one forward backward pass.
Definition:Iteration
Number of passes,each pass using [batch size] number of examples.batch-size取了多少次。
import torch # Dataset is an abstract class.We can define our class inherited from this class. from torch.utils.data import Dataset # DataLoader is a class to help us loading data in PyTorch. from torch.utils.data import DataLoader # DiabetesDataset is inherited from abstract class Dataset. classDiabetesDataset(Dataset): def__init__(self): pass # The expression,dataset[index] will call this magic function. def__getitem__(self, index): pass # This magic function returns length of dataset. def__len__(self): pass # Construct DiabetesDataset object dataset = DiabetesDataset() # Initialize loader with batch-size, shuffle,process number(进程数). train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
ExtraL num_workers in Windows
1 2 3 4 5 6
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2) ...... # enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。 for epoch inrange(100): for i, data inenumerate(train_loader, 0): ......
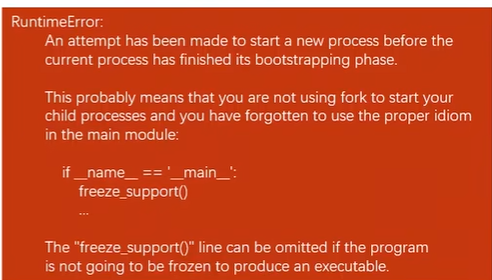
The implementation of multiprocessing is different on Windows,which uses spawn instead of fork.
So we have to wrap (包裹)the code with an if-clause to protect the code from executing multiple times.
1 2 3 4
if_name_ == '_main_': for epoch inrange(100): for i, data inenumerate(train_loader, 0): # 1.Prepare data
import torch # For constructing DataLoader from torchvision import transforms from torchvision import datasets from torch.utils.data import DataLoader # For using function relu() import torch.nn.functional as F # For constructing Optimizer import torch.optim as optim
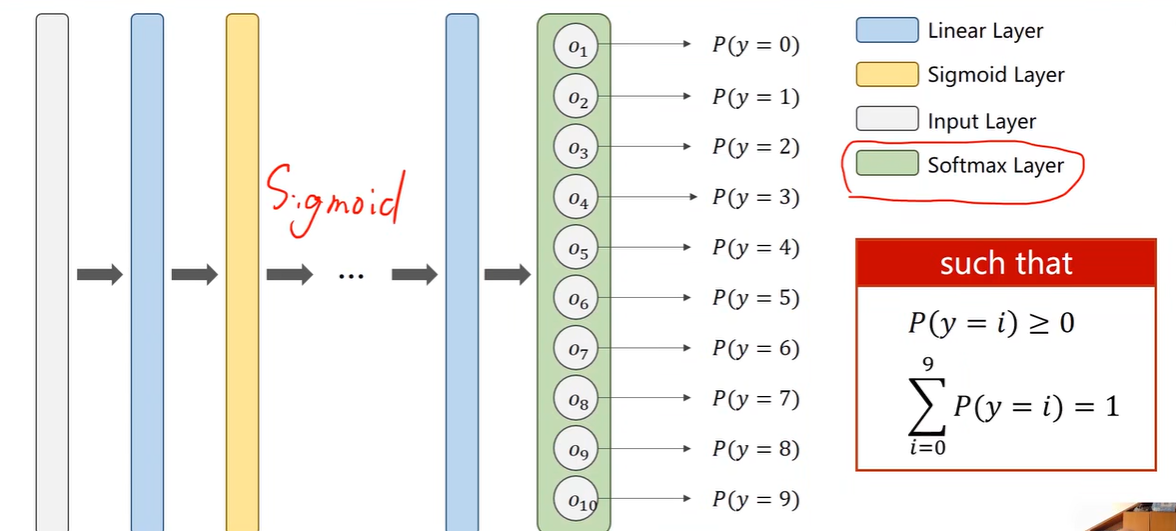
defforward(self, x): x = x.view(-1, 784) x = F.relu(self.l1(x)) x = F.relu(self.l2(x)) x = F.relu(self.l3(x)) x = F.relu(self.l4(x)) # 最后一层不用激活,直接输入softmax return self.l5(x) model = Net()
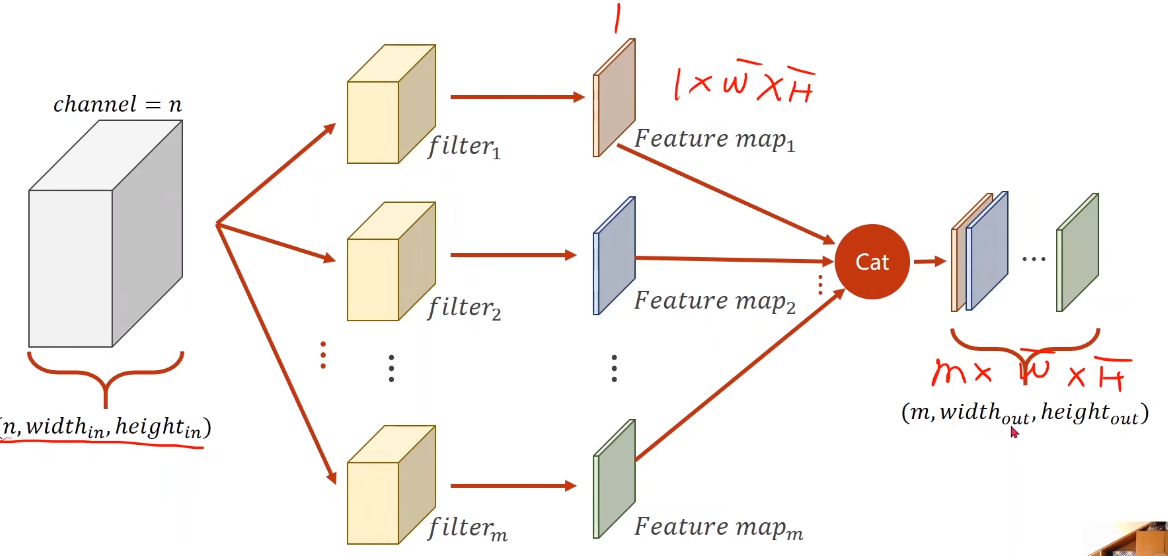
defforward(self, x): # Flatten data from(n, 1, 28, 28) to (n, 784) # 样本数量 batch_size = x.size(0) x = F.relu(self.pooling(self.conv1(x))) x = F.relu(self.pooling(self.conv2(x))) x = x.view(batch_size, -1) # flatten x = self.fc(x) return x
defforward(self, x): # Flatten data from(n, 1, 28, 28) to (n, 784) # 样本数量 batch_size = x.size(0) x = F.relu(self.pooling(self.conv1(x))) x = F.relu(self.pooling(self.conv2(x))) x = x.view(batch_size, -1) # flatten x = self.fc(x) return x
model = Net() # Define device as the first visible cuda device if we have CUDA available. device = torch.device("cuda:0"if torch.cuda.is_available() else"cpu") # Convert parameters and buffers of all modules to CUDA Tensor. model.to(device)
Move Tensors to GPU
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
deftrain(epoch): running_loss = 0.0 for batch_idx, data inenumerate(train_loader, 0): inputs, target = data # Send the inputs and targets at every step to the GPU. inputs, target = inputs.to(device), target.to(device) optimizer.zero_grad() # forward + backward + update outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step()
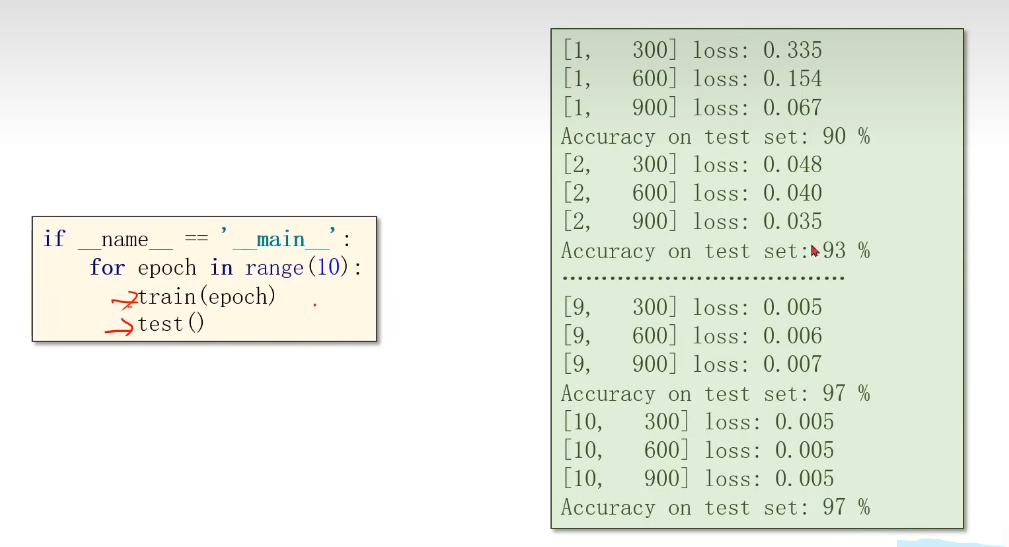
deftest(): correct = 0 total = 0 with torch.no_grad() for data in test_loader images, labels = data # Send the inputs and targets at every step to the GPU. images, labels = images.to(device), labels.to(device) outputs = model(images) -, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy on test set: %d %%' % (100 * correct / total))