PyTorch Learning 2
7 Tensorboard的使用(一)
打开Pycharm,设置环境
1 | |
add_scalar()方法

1 | |
安装TensorBoard
安装后再次运行,左侧多了一个logs文件

终端输入
1 | |
指定端口
1 | |
访问端口,显示图像
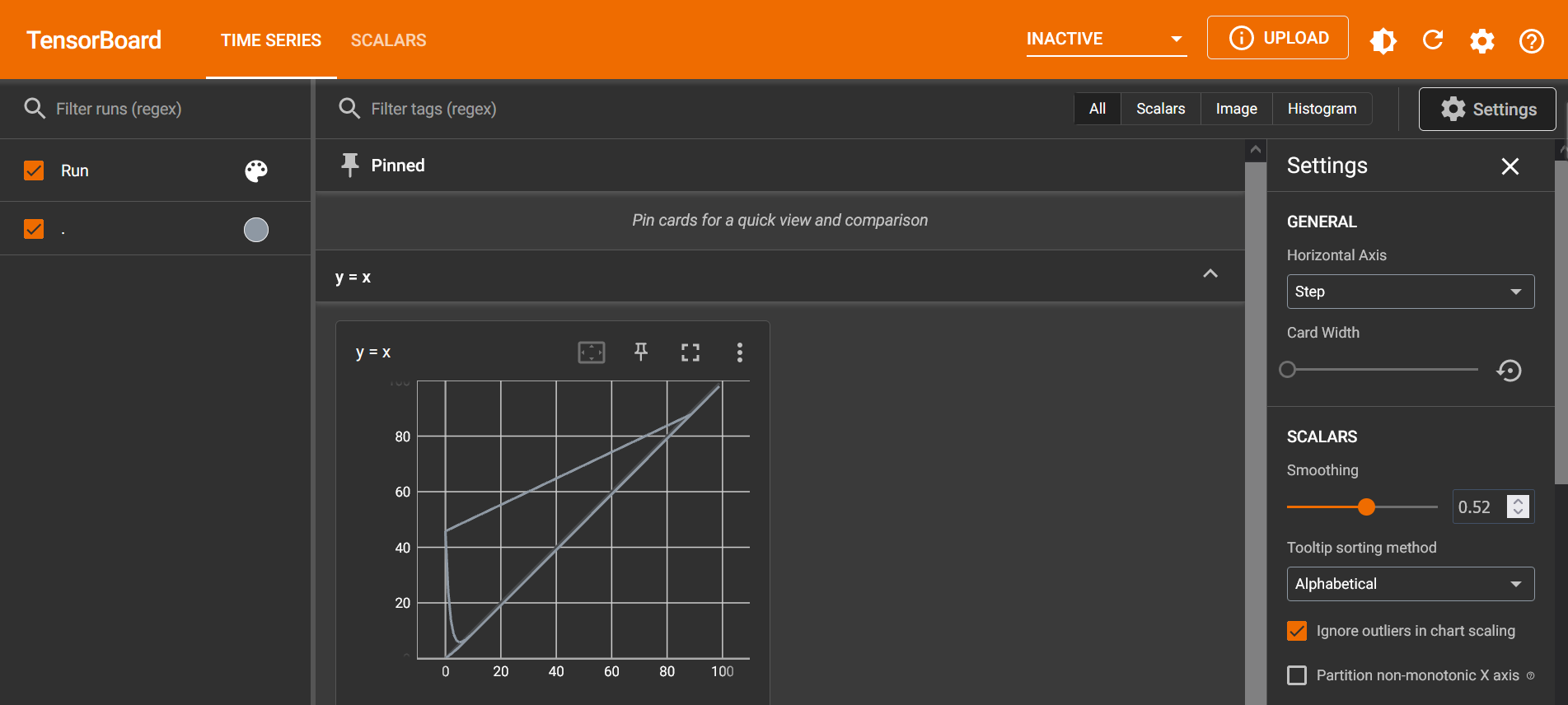
绘制y=2x
1 | |
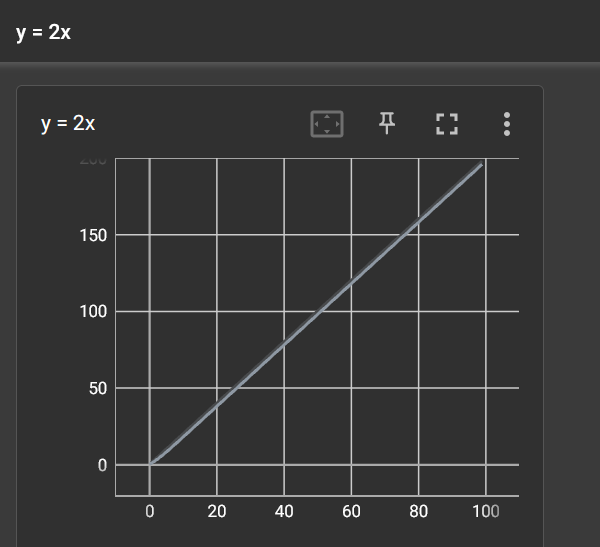
如果不改变add_scalar()函数的标题只改变参数
1 | |
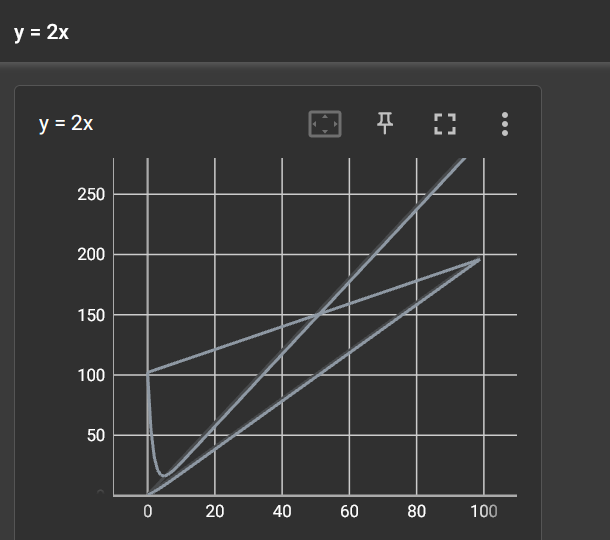

向writer中写入新的事件,同时也记录了上一个事件
解决方法:
一、删除logs下的文件,重新启动程序
二、创建子文件夹,也就是说创建新的SummaryWriter(“新文件夹”)
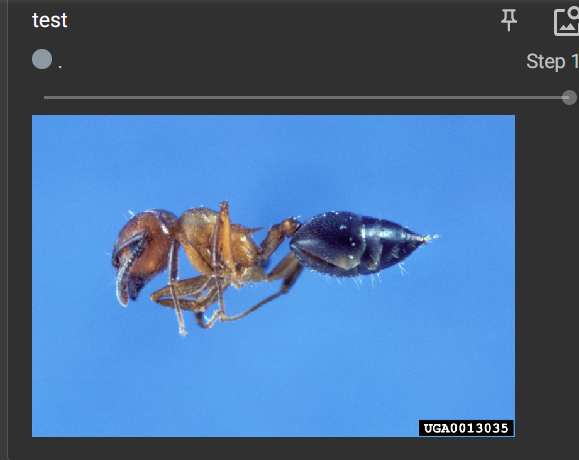
8 TensorBoard的使用(二)add image()的使用(常用来观察训练结果)
控制台输入
1 | |
利用numpy.array(),对PIL图片进行转换
NumPy型图片是指使用NumPy库表示和处理的图像。NumPy是一个广泛使用的Python库,用于科学计算和数据处理。它提供了一个多维数组对象(ndarray),可以用于存储和操作大量的数值数据。在图像处理领域中,NumPy数组通常用来表示图像的像素值。
NumPy数组可以是一维的(灰度图像)或二维的(彩色图像)。对于彩色图像,通常使用三维的NumPy数组表示,其中第一个维度表示图像的行数,第二个维度表示图像的列数,第三个维度表示图像的通道数(例如,红、绿、蓝通道)
控制台
1 | |
文件内
1 | |
从PIL到numpy, 需要在add image()中指定shape中每一个数字/维表示的含义。
打开端口,显示图像
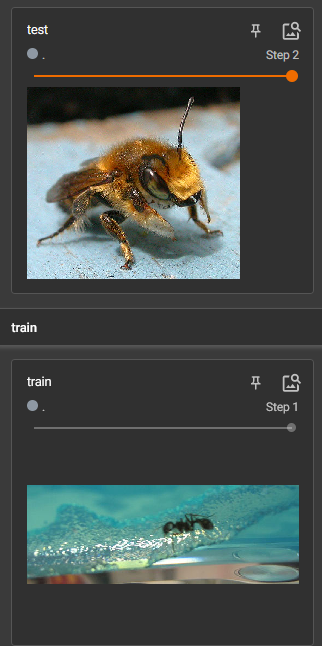
添加蜜蜂图片,修改步长为2
1 | |

更换标题
1 | |
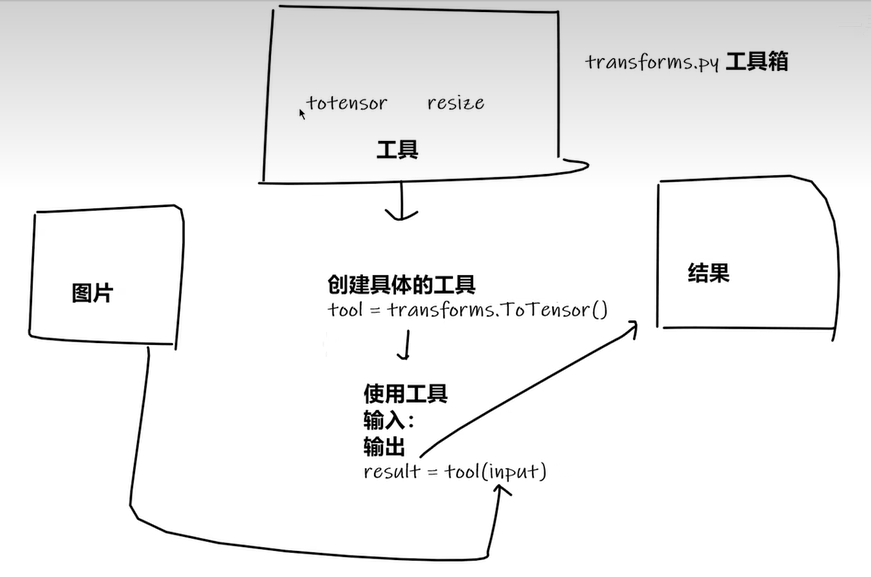
9 Transforms 的使用(一)
transforms结构及用法
ctrl+p可提示函数需要什么参数
1 | |
10Transforms的使用(二)
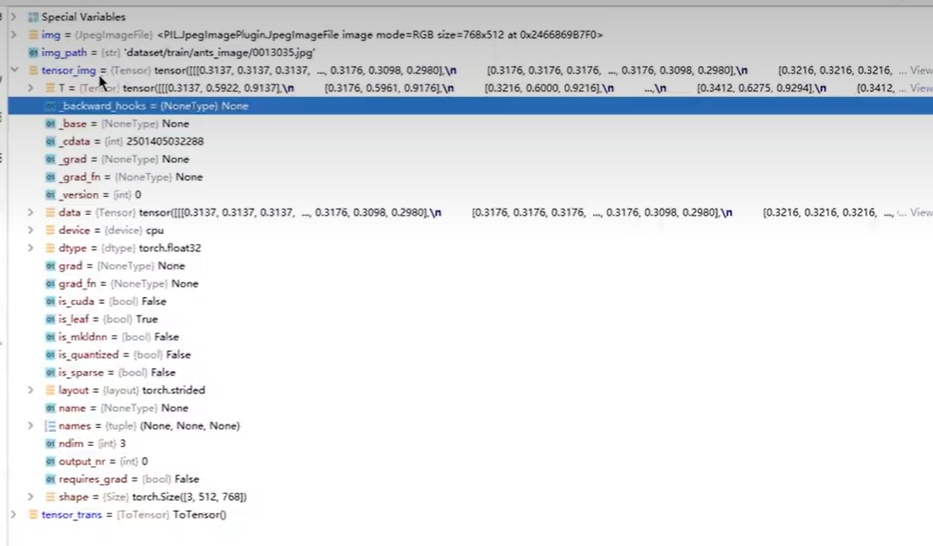
Tensor包括深度学习需要的参数
下载Opencv
终端输入
1 | |
控制台
1 | |
利用Tensor_img显示图片
1 | |
终端输入
1 | |
打开端口,显示图片
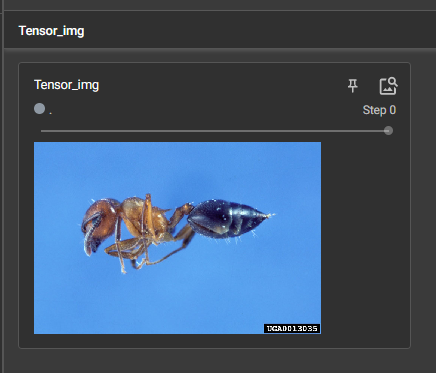
11 常见的Transforms(一)
Pytorch中call()的用法
1 | |
ToTensor的使用
1 | |
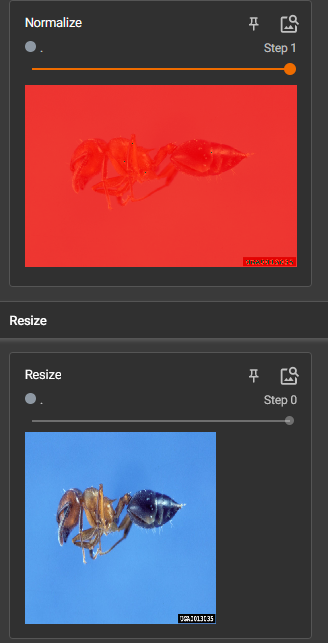
Normalize() 归一化 的使用

mean是均值,std是标准差
1 | |
输出归一化结果
1 | |
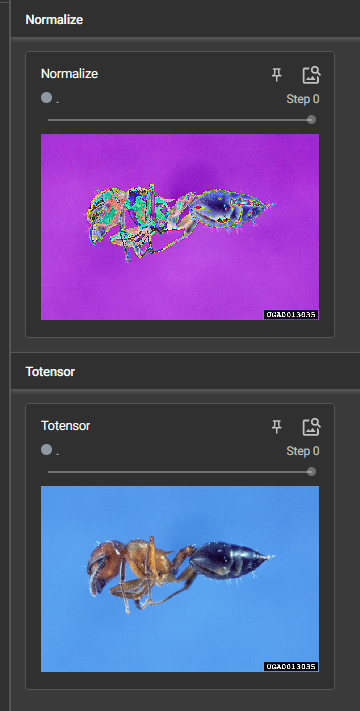
12 常见的Transforms(二)
Resize()的使用
1 | |
将PIL类型的img_resize转为tensor类型
1 | |
图片大小改变
Compose()的使用
将不同的操作组合起来,按顺序执行。前一步的输出是下一步的输入,要对应。
Compose()中的参数需要是一个列表。Python中,列表的表示形式为[数据1,数据2,…]。在Composel中,数据需要是transforms类型,所以得到,Compose([transforms参数1,transforms参数2,…])
RandomCrop()随机裁剪的用法
1 | |
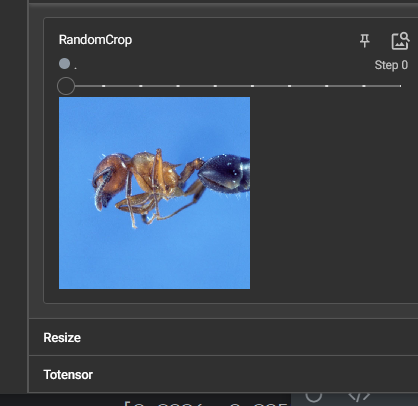
总结使用方法
- 关注输入和输出类型
- 多看官方文档
- 关注方法需要什么参数
- 不知道返回值的时候
- print()
- print(type())
- debug
13 torchvision中的数据集使用
下载训练集和测试集
1 | |
可以用迅雷加快下载速度
1 | |
classes内表示每种target对应哪种类别
1 | |
添加Transform参数
1 | |
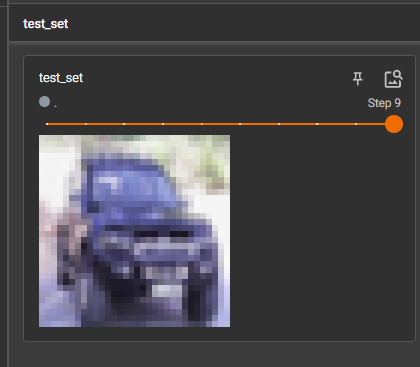
14 DataLoader的使用
测试数据集中第一张图片及target
1 | |

理解batch_size
1 | |
更改batch_size=64
1 | |
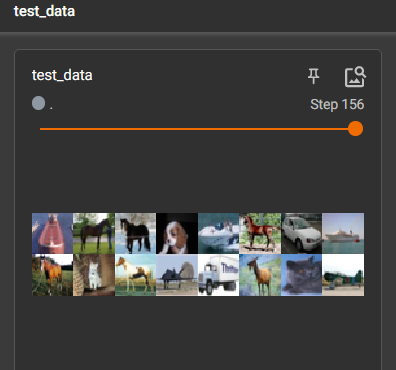
drop_last设置为false,所以不会丢掉数量小于batch_seze的组。
理解shuffle
添加epoch
1 | |
shuffle为false时两轮图片加载中随机选取结果相同