Deep Learning 1
1 深度学习要解决的问题
机器学习流程
- 数据获取
- 特征工程(重点)
- 建立模型
- 评估与应用
特征工程的作用
- 数据特征决定了模型的上限
- 预处理和特征提取是最核心的
- 算法与参数选择决定了如何逼近这个上限
深度学习相比机器学习的优势是能够利用神经网络提取计算机能够识别的特征。
2 深度学习应用领域
无人驾驶,人脸识别,医学检测,屏幕变脸,分辨率重构
问题:参数很多,移动端速度可能比较慢
3 计算机视觉任务
图像分类任务
计算机视觉
- 图像表示:计算机眼中的图像
- 一张图片被表示成三维数组的形式,每个像素的值从0到255
- 例如:3001003
计算机视觉面临的挑战
- 照射角度
- 形状改变
- 部分遮蔽
- 背景混入
4 视觉任务中遇到的问题
机器学习常规套路
- 收集数据并给定标签
- 训练一个分类器
- 测试,评估
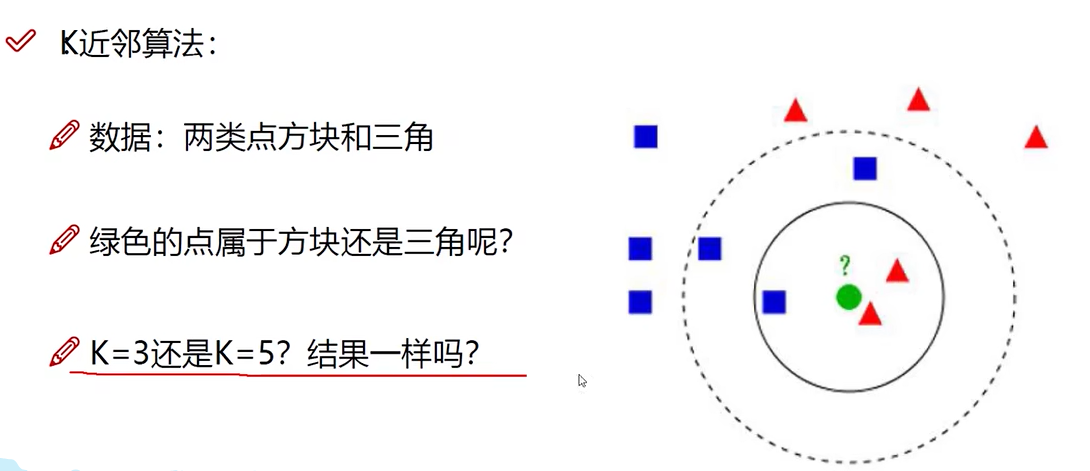
K近邻算法
K是半径。圆内哪种形状多绿色点就是哪种结果。
计算流程
- 计算已知类别数据集中的点与当前点的距离
- 按照距离依次排序
- 选取与当前点距离最小的K个点
- 确定前K个点所在类别的出现概率
- 返回前K个点出现频率最高的类别作为当前点预测分类
数据库样例CIFAR-10
简介
- 10类标签
- 50000个训川练数据
- 10000个测试数据
- 大小均为32*32(像素)

图像分类
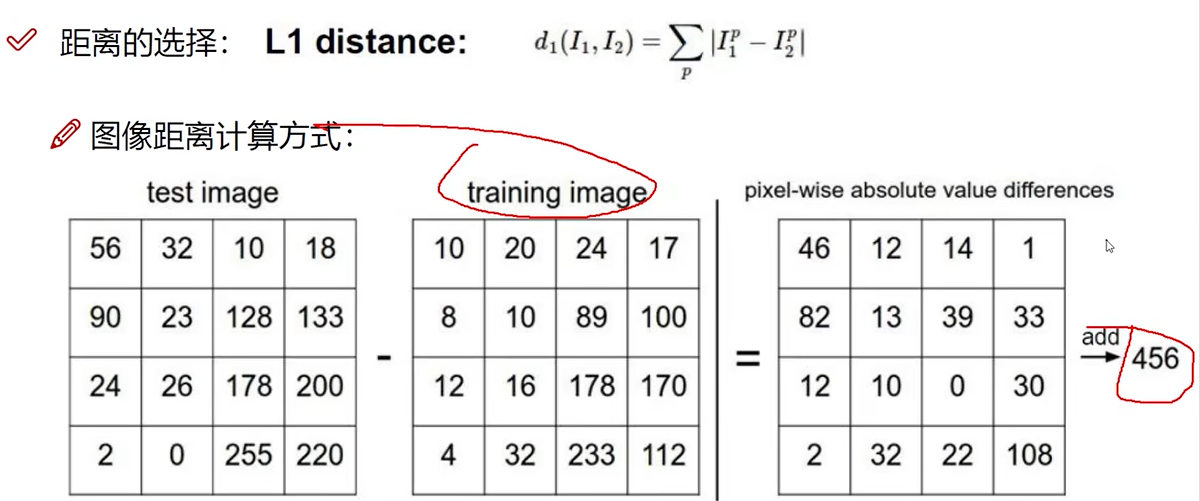
测试结果

为什么K近邻不能用来图像分类

5 得分函数
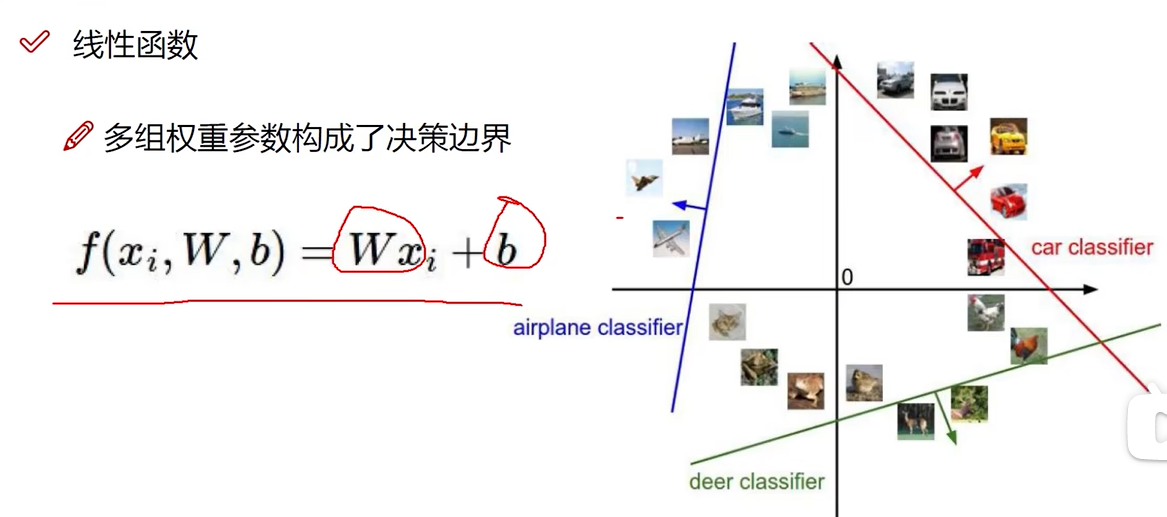
线性函数
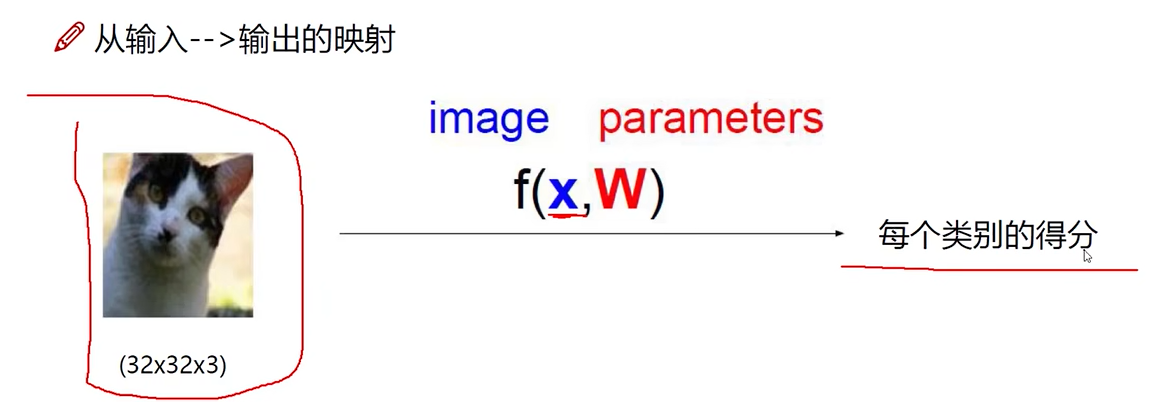
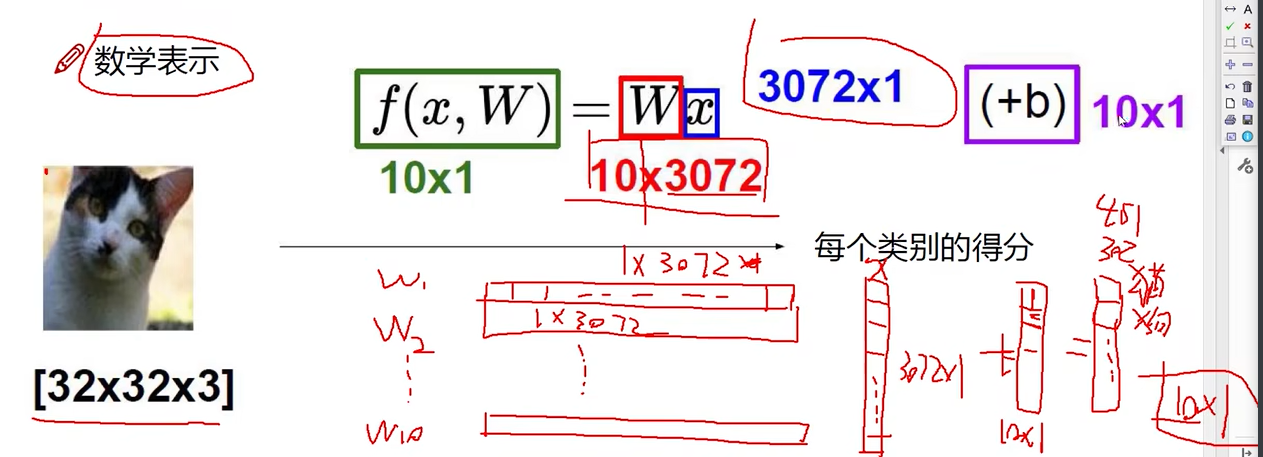
数学表示
10分类任务
Wi向量表示对于第i个类别,3072个像素点的权重。i = 1, 2, 3….10
b代表对10个不同类别分别进行微调
6 损失函数的作用
线性函数计算方法
3分类问题为例
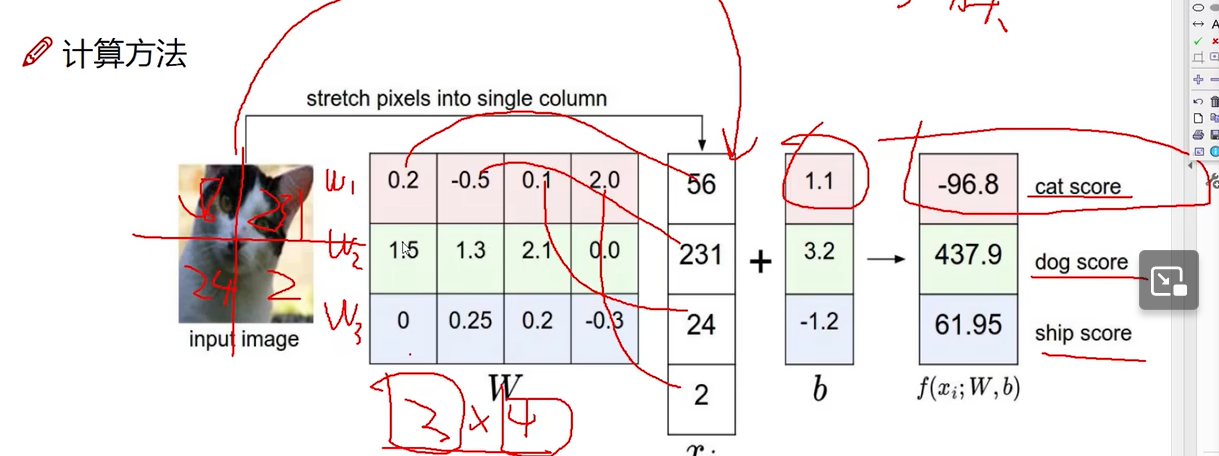
权重参数越大,代表该像素点对于该类别越重要。正代表越接近该类别,负代表越不接近该类别。
W矩阵开始可以随机产生,迭代过程中调整。
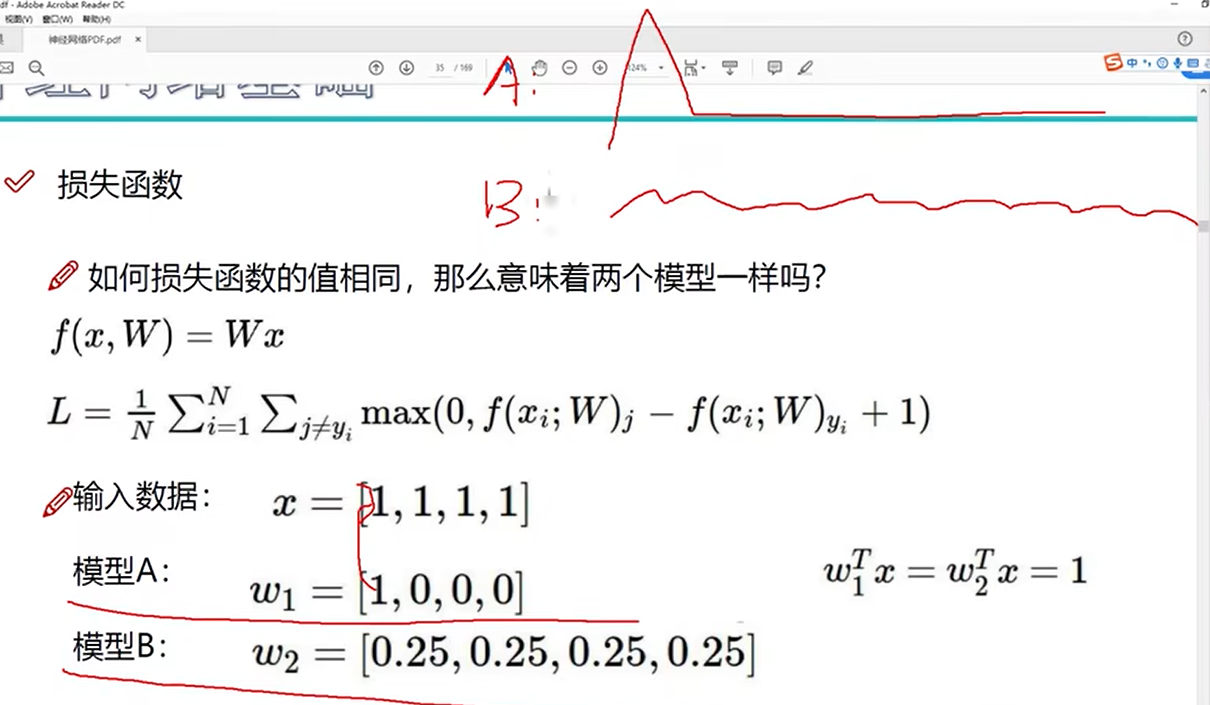
损失函数

举例
sj-sy+1代表错误类别得分-正确类别+1
1代表容忍程度,正确类别得分至少比错误大1才能说明神经网络具备分类能力

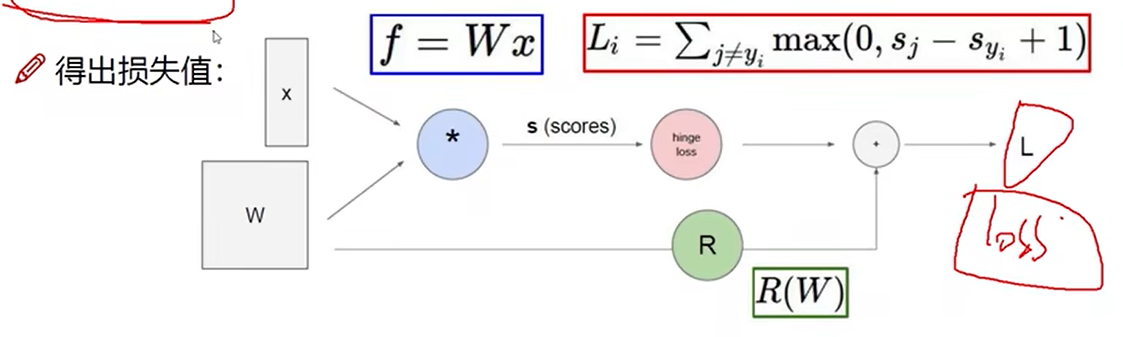
7 前向传播整体流程
损失函数
正则化惩罚项
由于权重参数带来的损失

softmax分类器
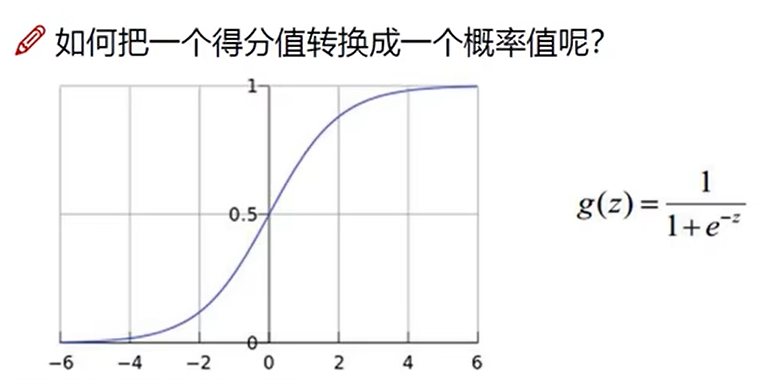
归一化normalize
概率越大,损失应该越小

前向传播
8 反向传播计算方法
反向传播
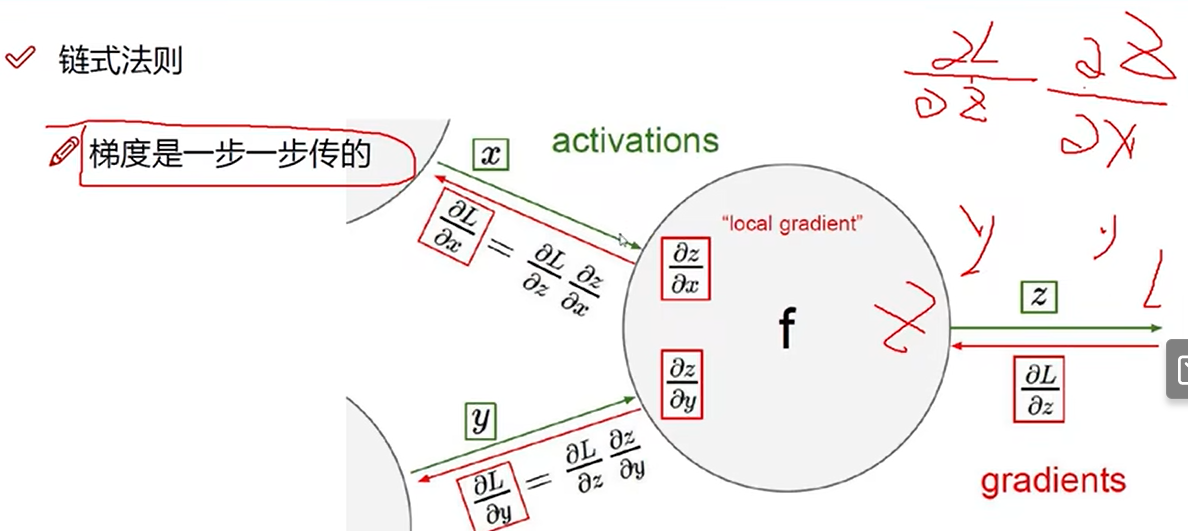
逐层求偏导
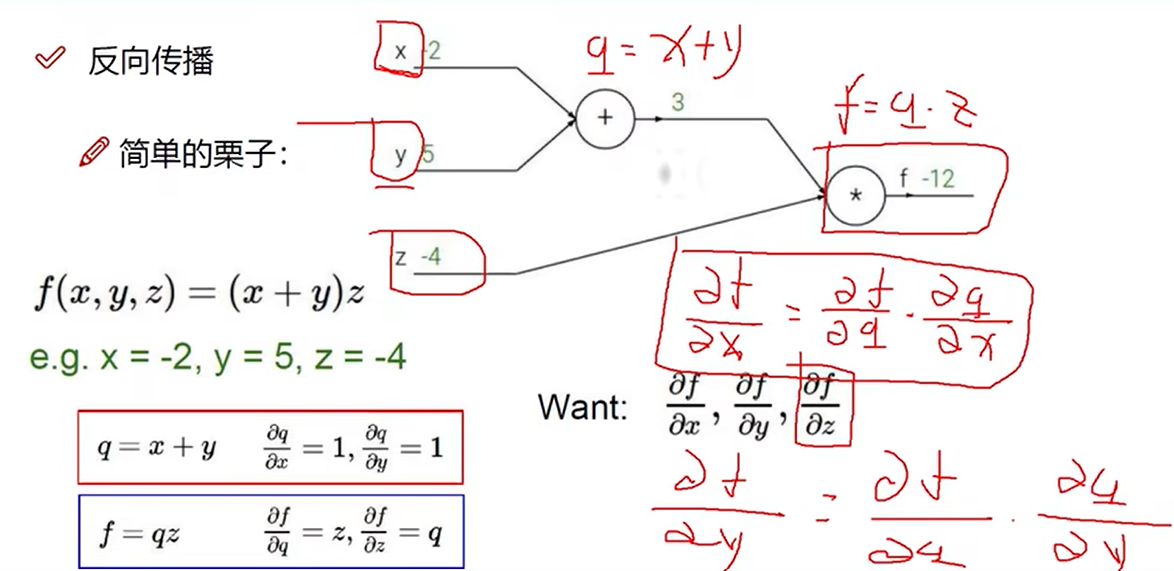
链式法则
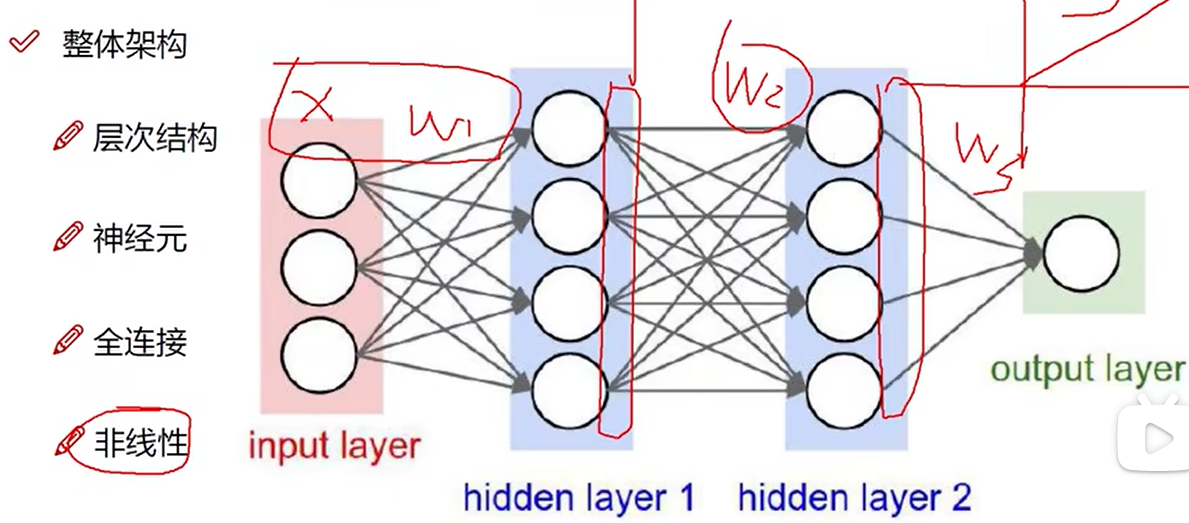
9 神经网络整体架构
示例
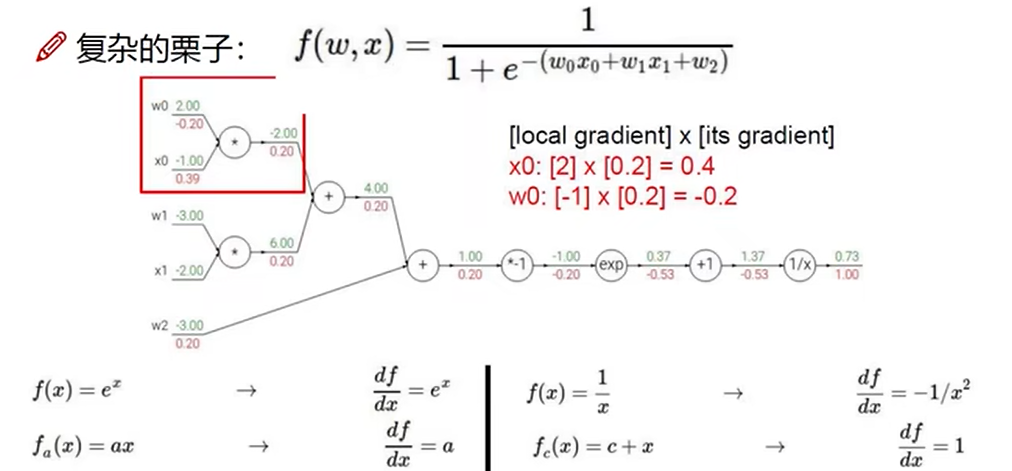
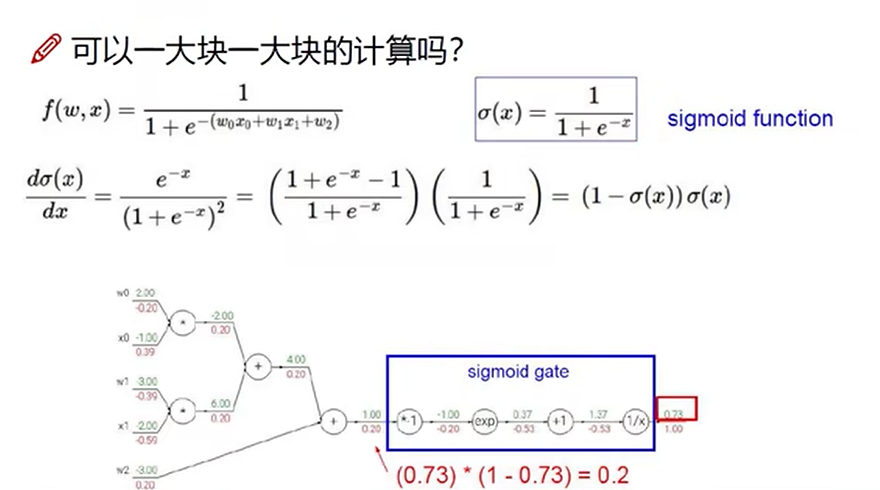
反向传播可以一大块一大块计算
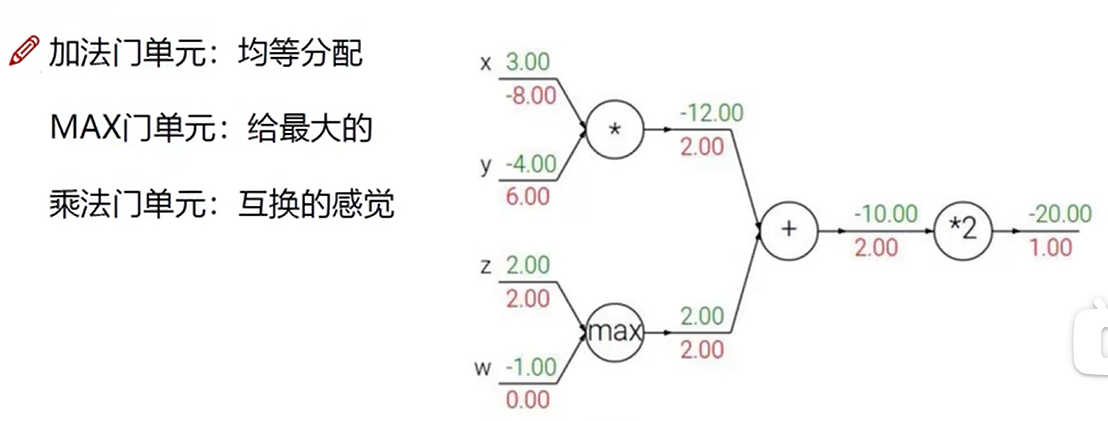
门单元
梯度角度考虑
10 神经网络整体架构细节
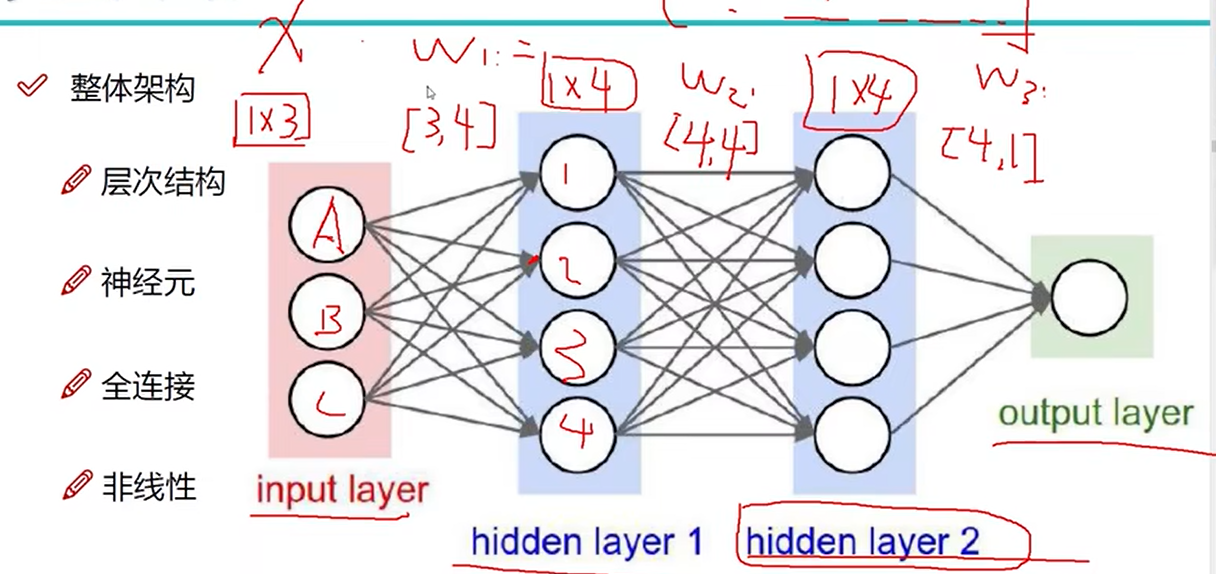
非线性
如max(0,x)
在每一步矩阵计算之后添加非线性
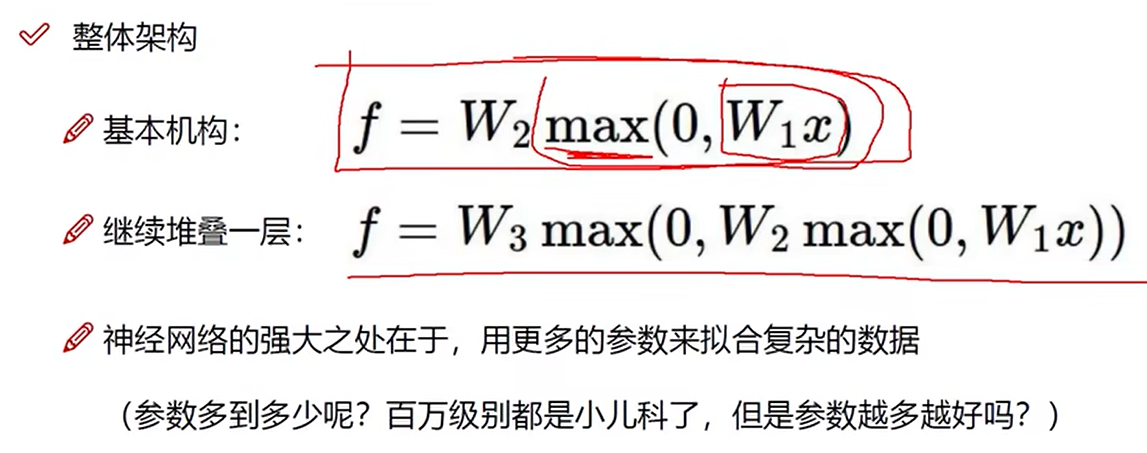
11 正则化与激活函数
正则化的作用
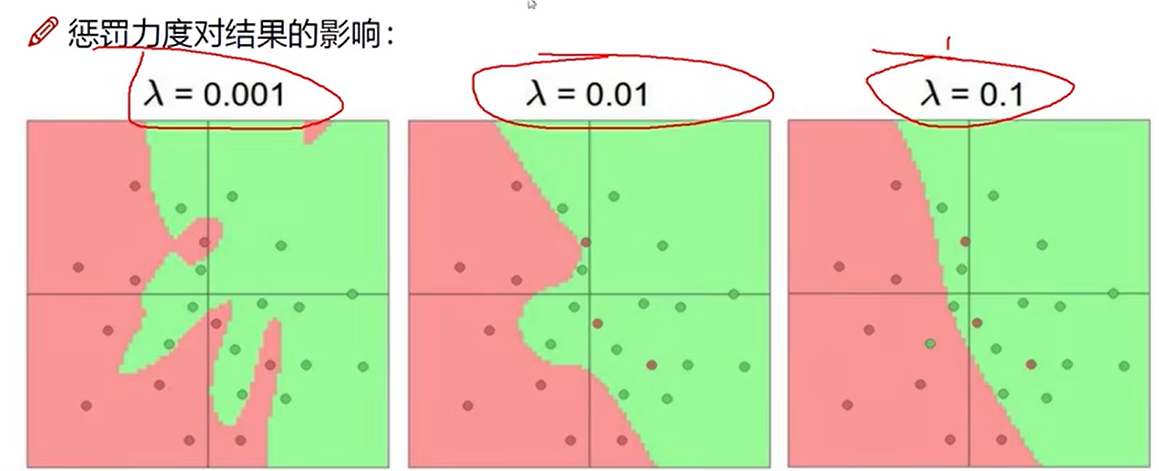
λ太小容易过拟合
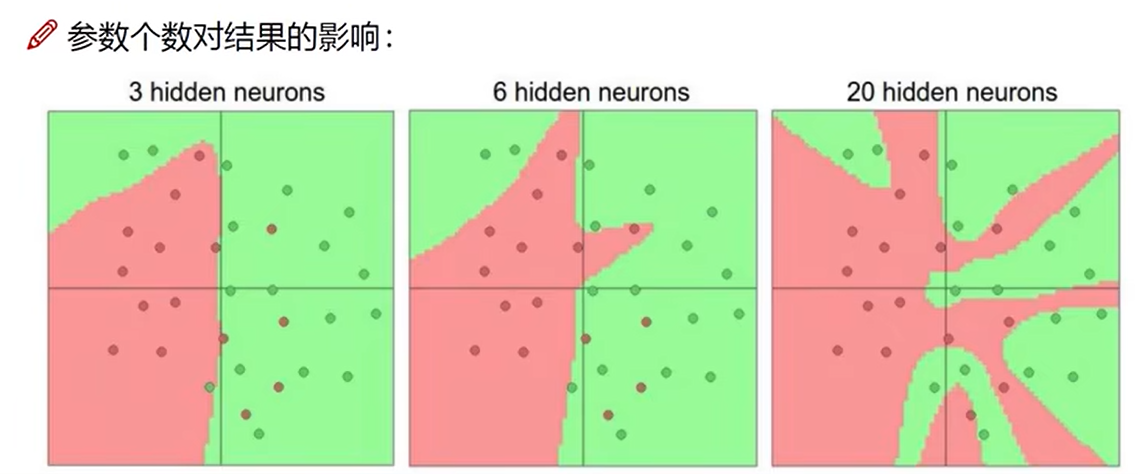
参数个数对结果的影响
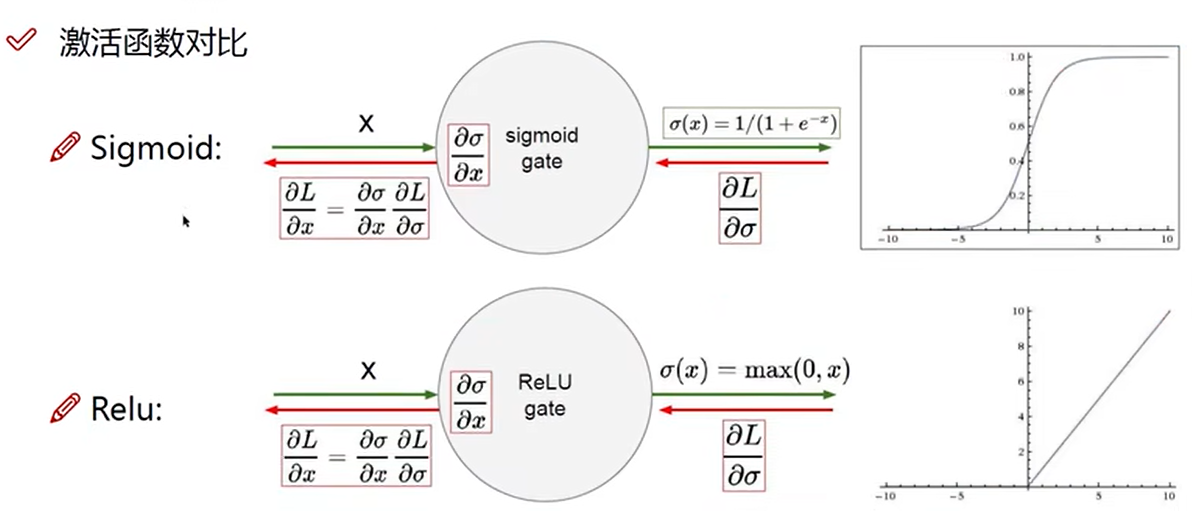
激活函数
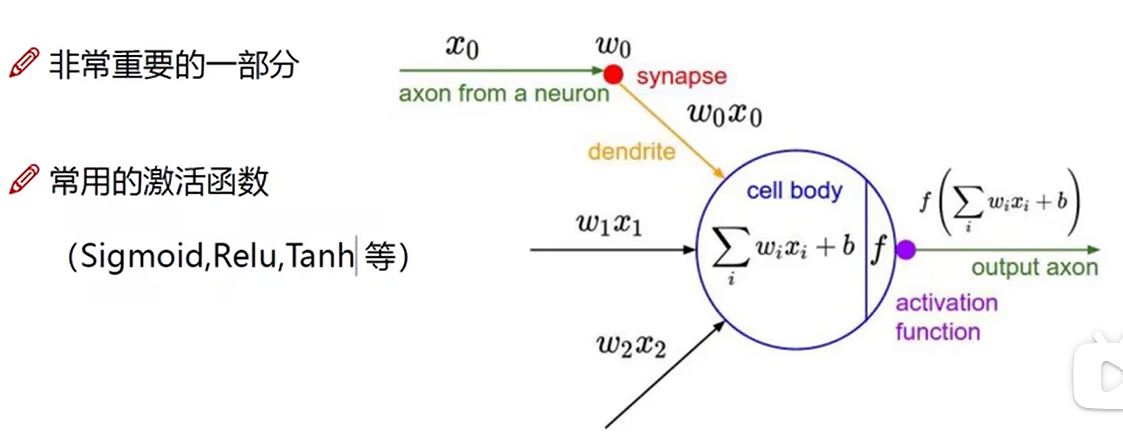
激活函数对比
Sigmoid可能会出现梯度消失
12 神经网络过拟合解决方法
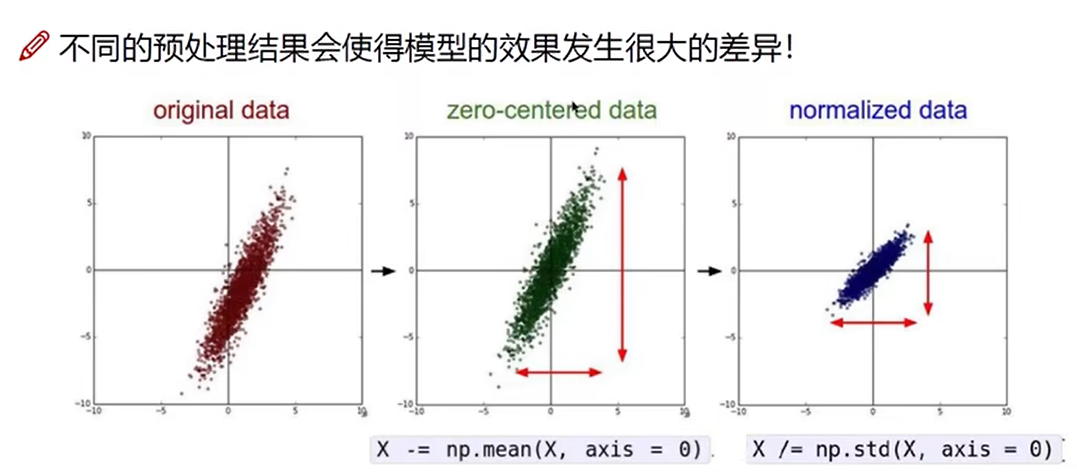
数据预处理
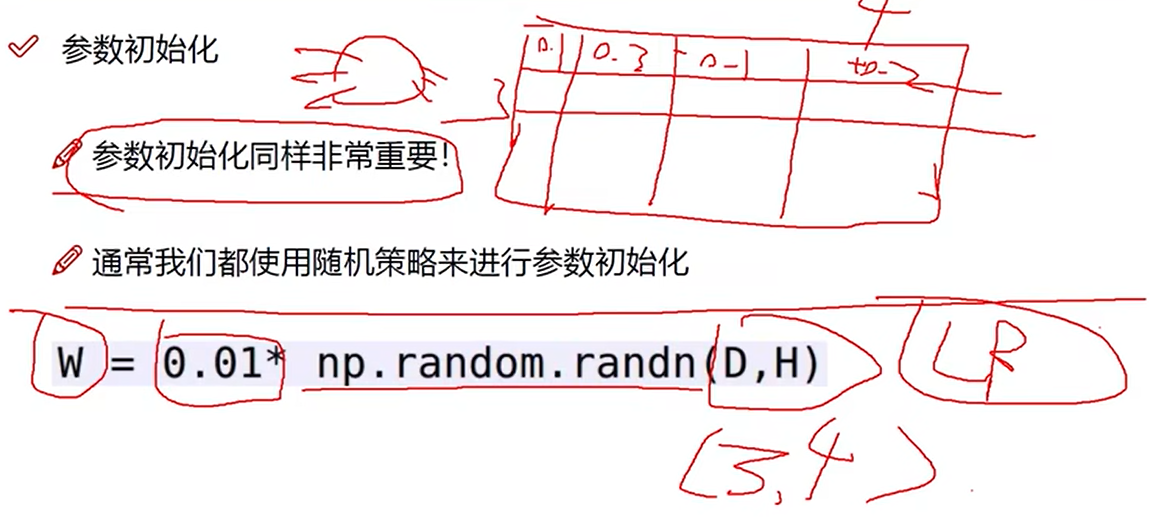
参数初始化
乘上0.01使得权重差异不会过大
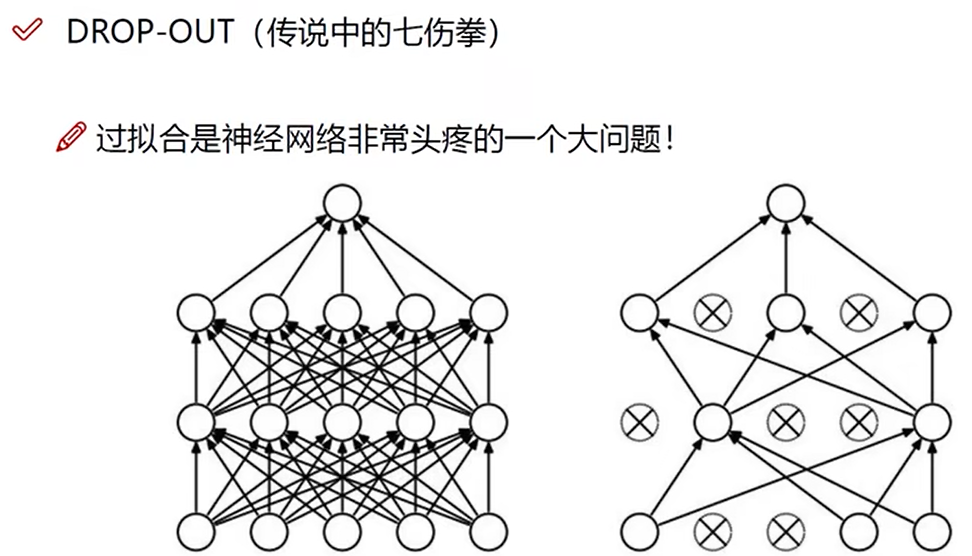
DROP-OUT
每一次训练过程中,每一层随机杀死一部分神经元,不更新参数,目的是降低过拟合风险。不同的训练随机选择不同的神经元杀死。测试阶段不杀死,用所有神经元测试。
13 卷积神经网络应用领域
检测任务,分类与检索,超分辨率重构,医学任务,无人驾驶,人脸识别
14 卷积的作用
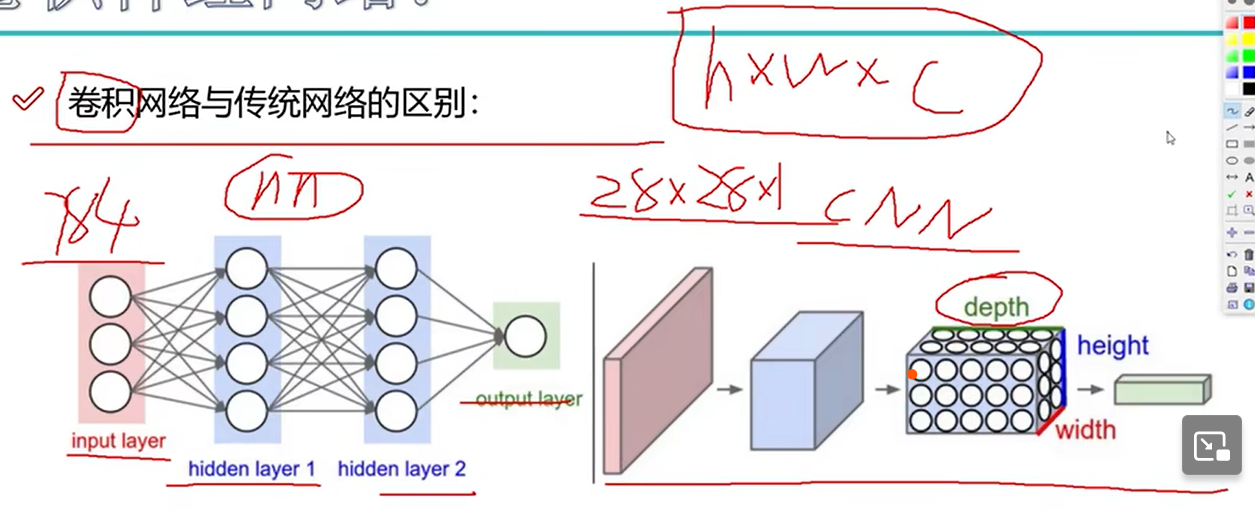
卷积网络与神经网络的区别
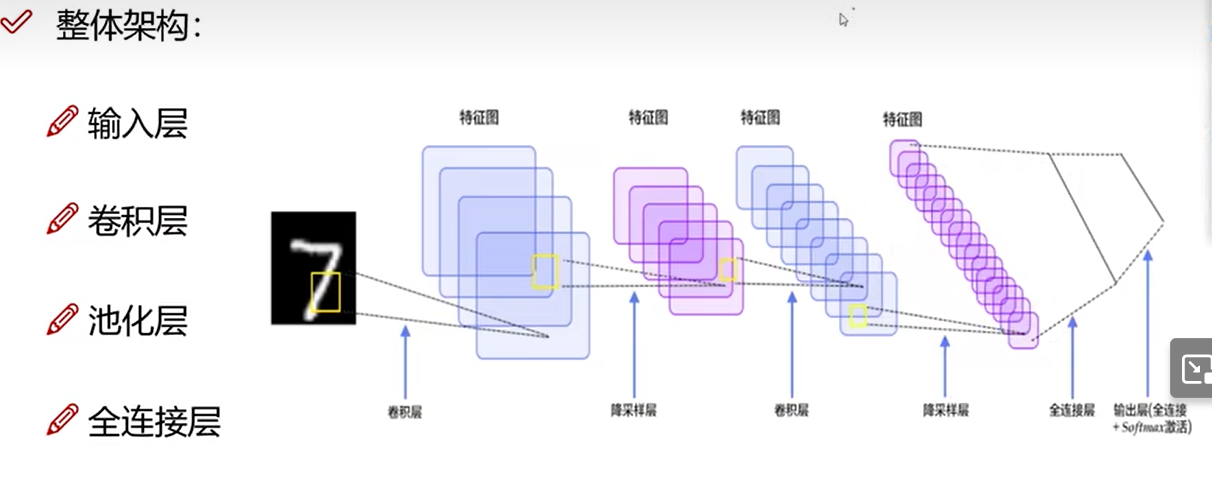
整体架构
卷积
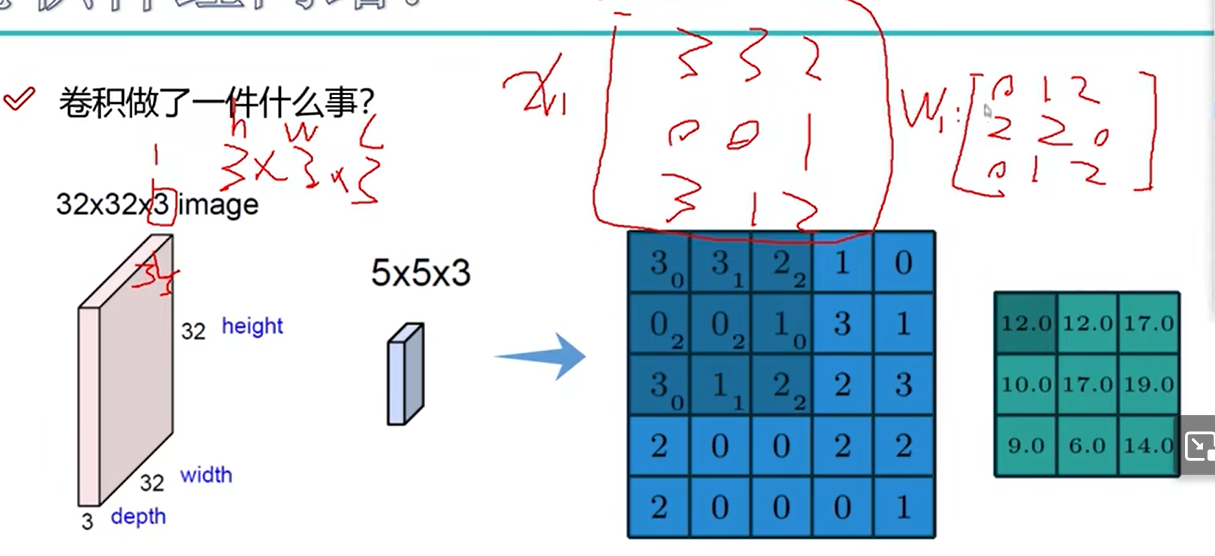
15 卷积特征值计算方法
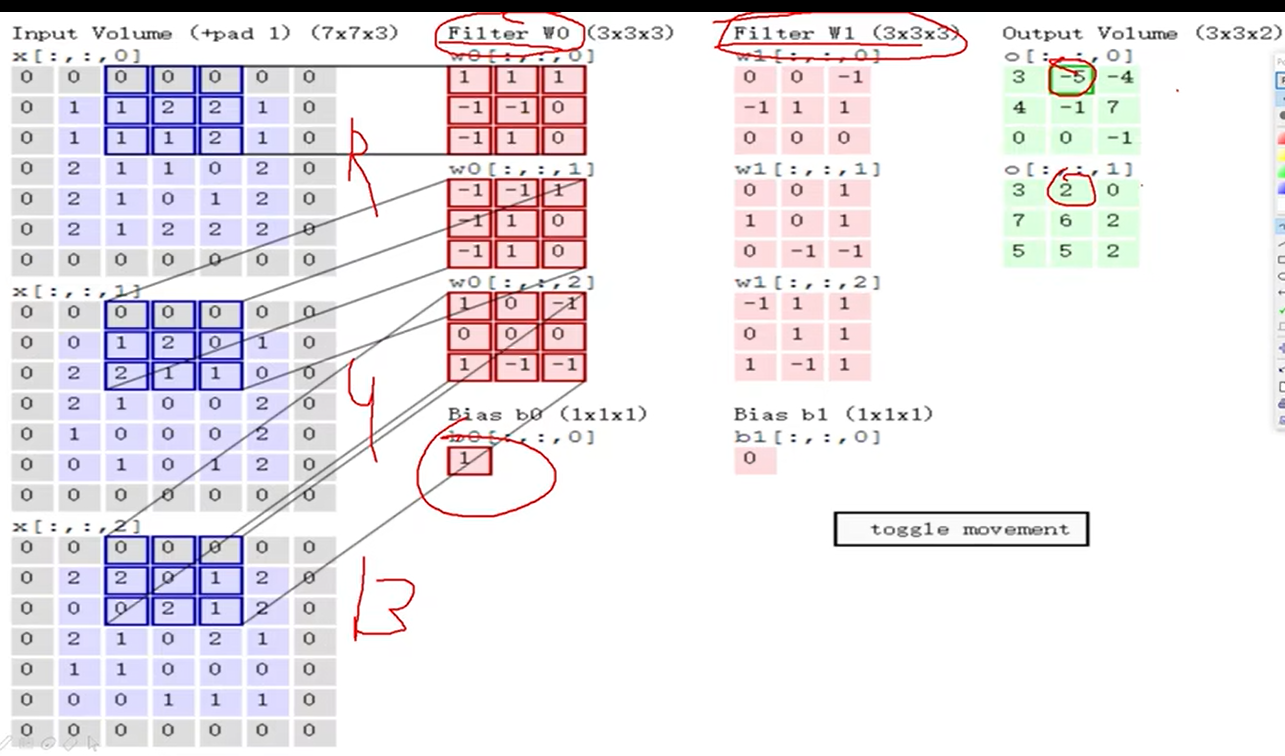
图像颜色通道

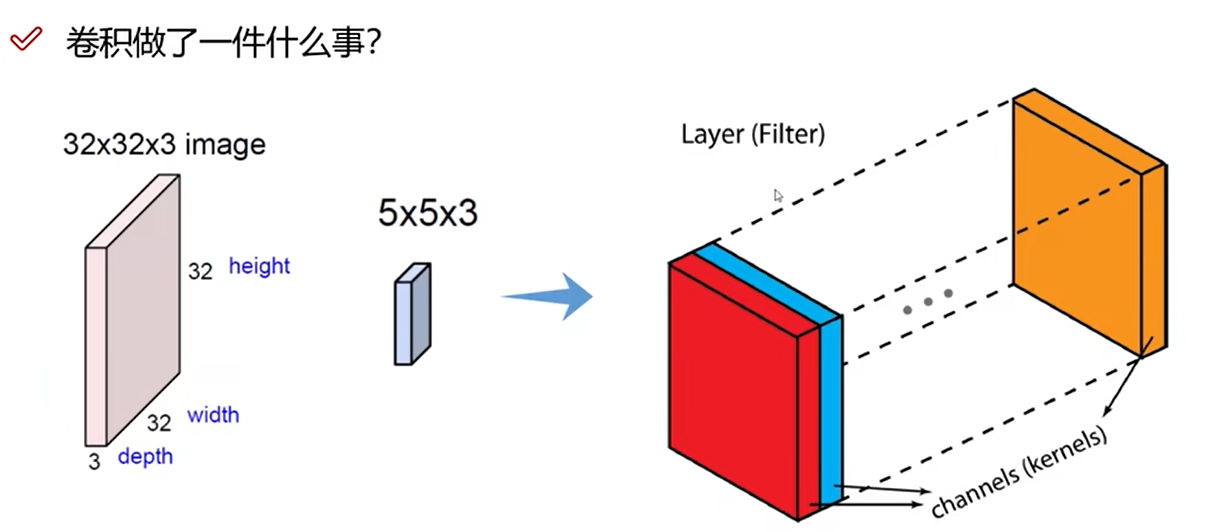
输入的通道数为3,每个卷积核也有3个通道。每个通道卷积,三个通道结果相加,再加偏置
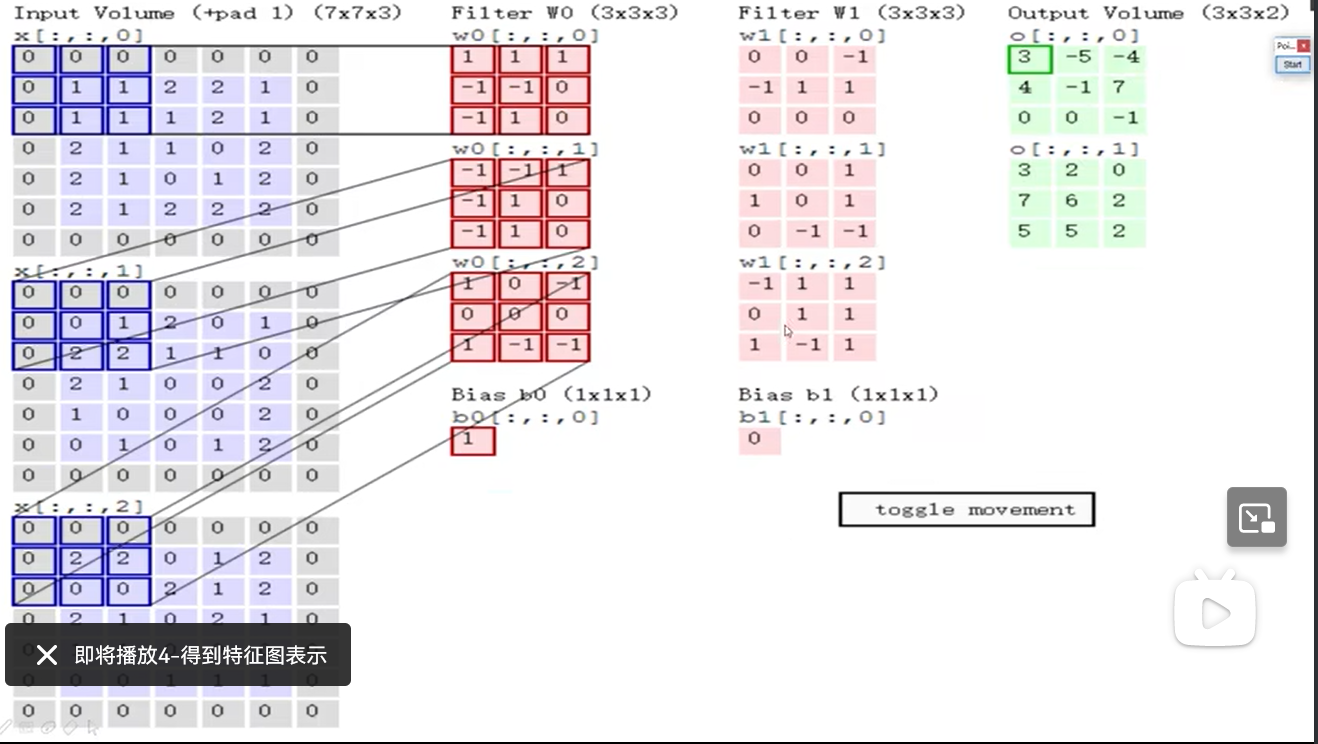
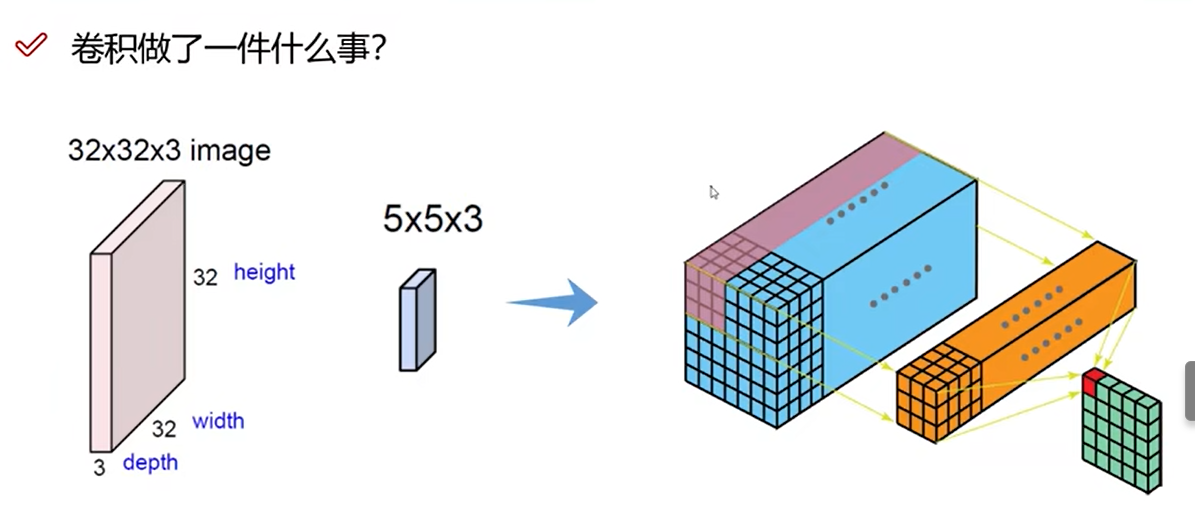
16 得到特征图表示
特征图个数
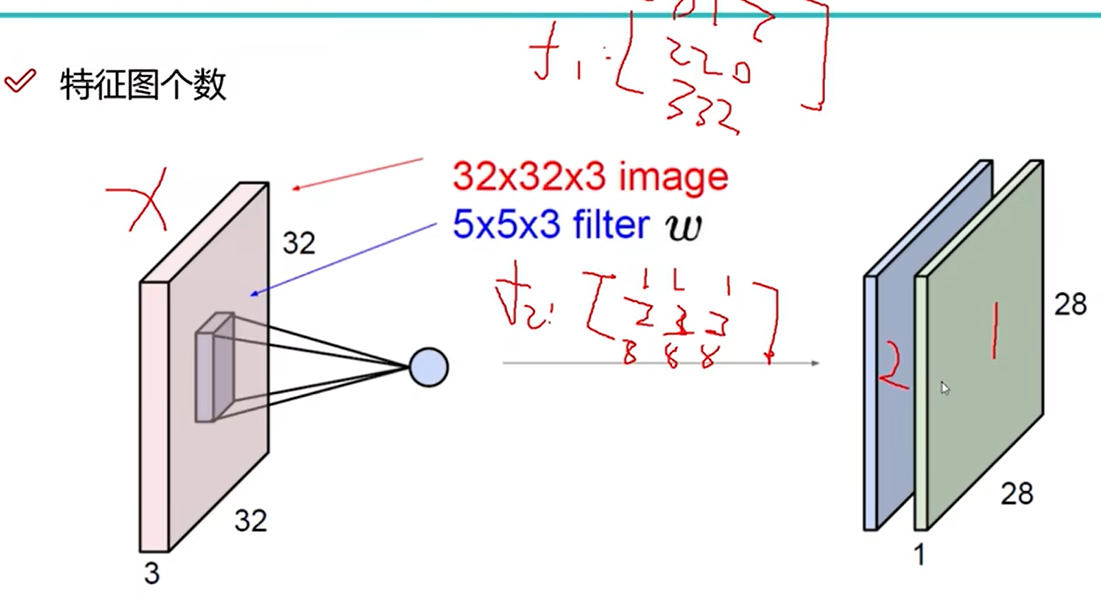
特征图个数与卷积核相同
两个卷积核W0和W1,得到两个特征图
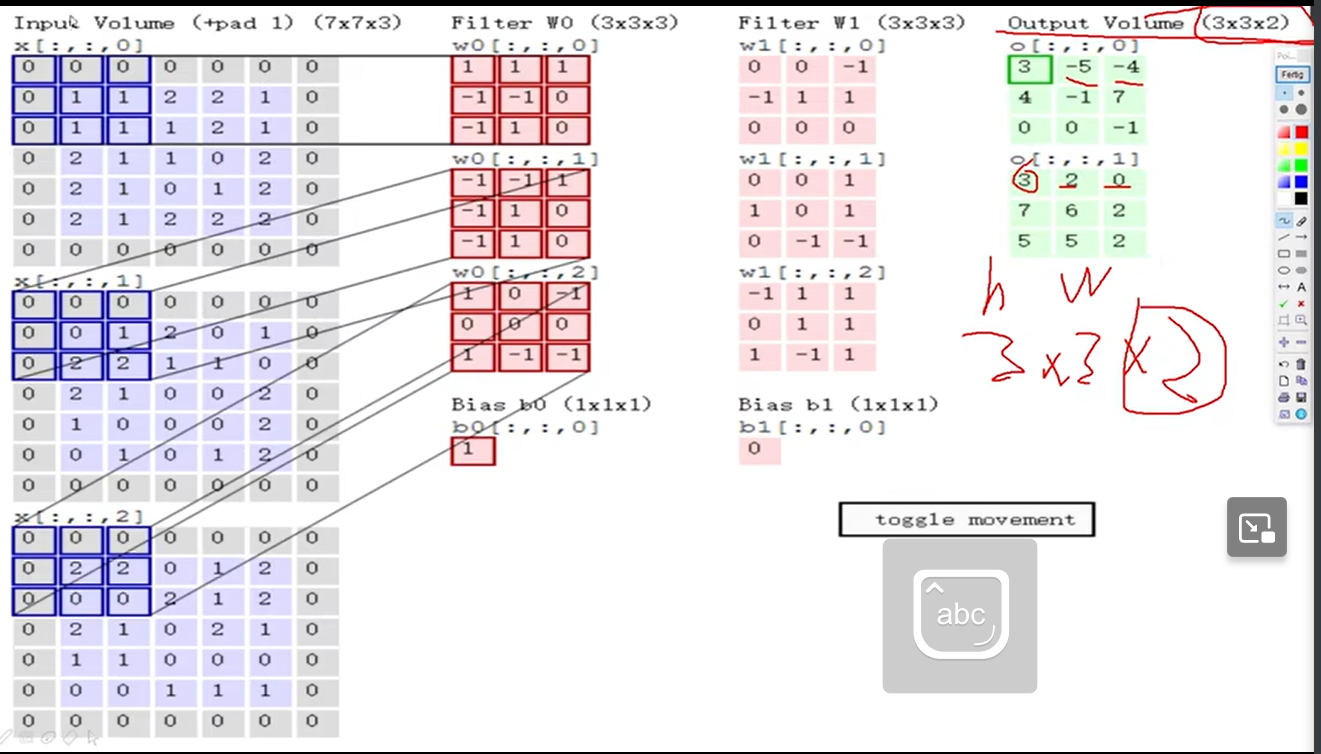
平移卷积核
17 步长与卷积核大小对结果的影响
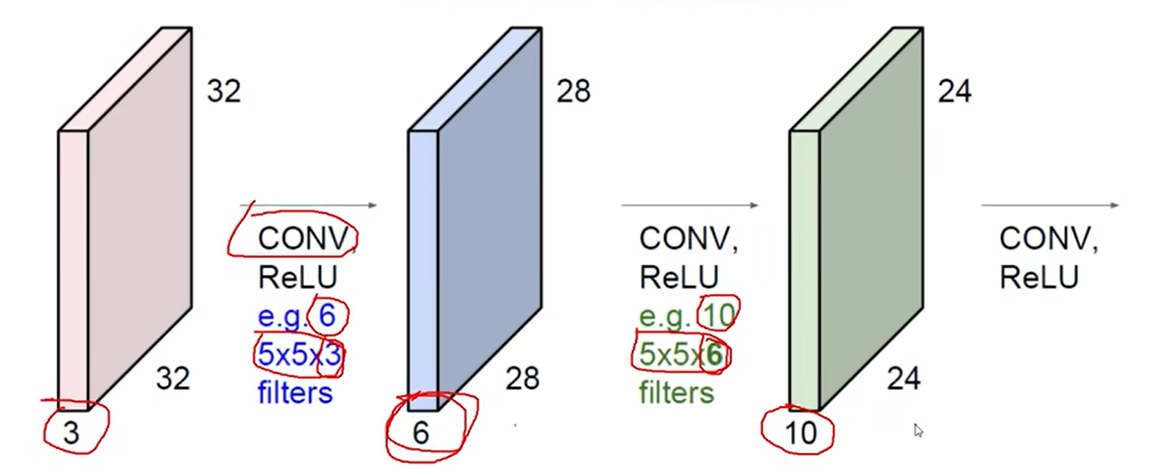
堆叠的卷积层
卷积核维度和输入维度相同,特征图深度和卷积核个数相同。
卷积层涉及参数
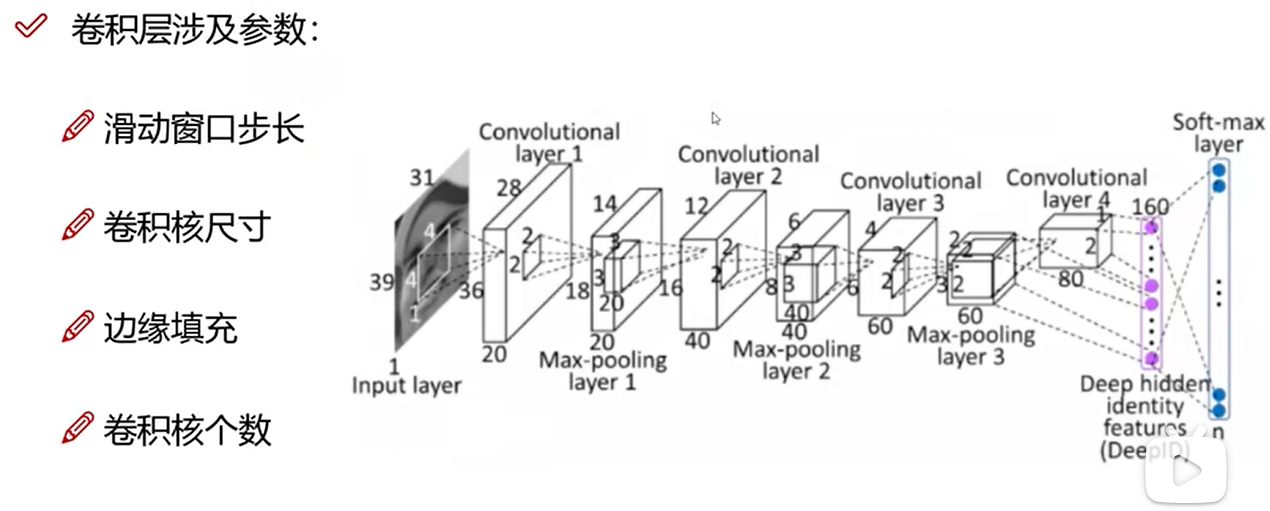
步长
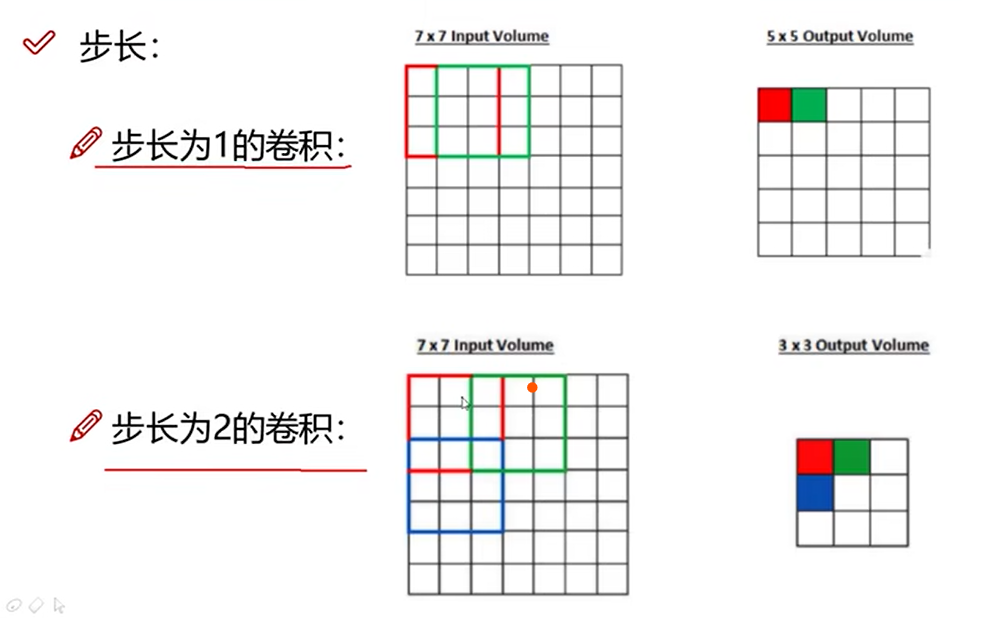
步长越大,提取特征越粗糙,得到的特征图越小。常用值为1.
卷积核尺寸
卷积核越大,特征图越小。
18 边缘填充方法
卷积核移动后可能有重叠,部分点重复计算。边界点被利用次数比中间点少。为了使边界点利用更多一些,在图像外填充0。
卷积核个数
决定特征图个数。每个卷积核内的数字不同。
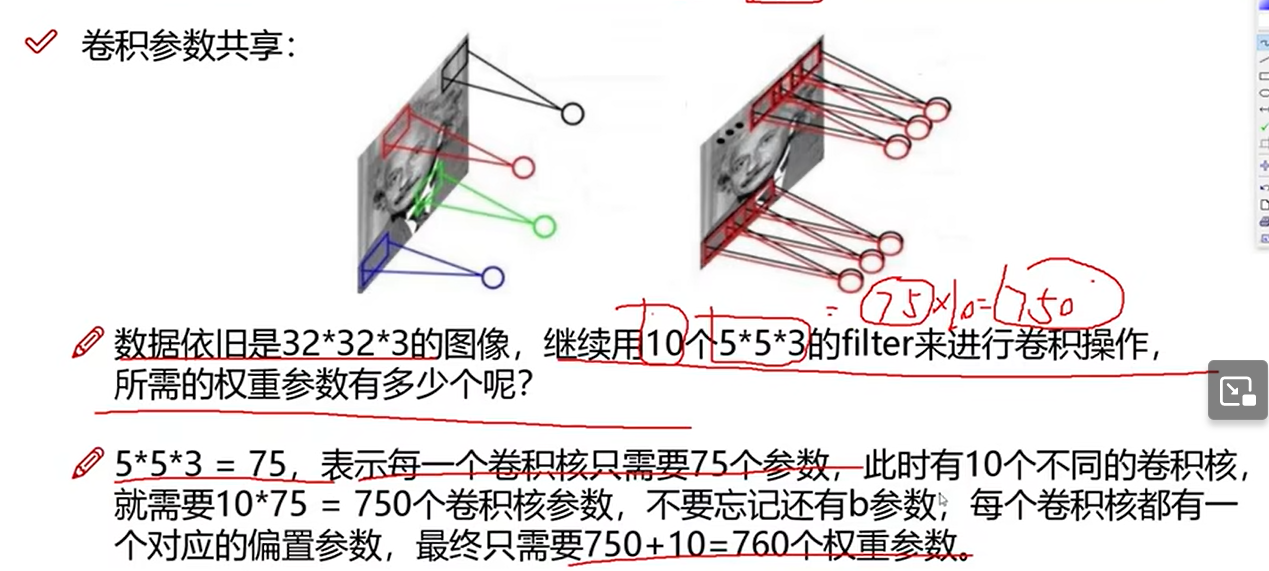
19 特征图尺寸计算与参数共享
卷积结果计算公式
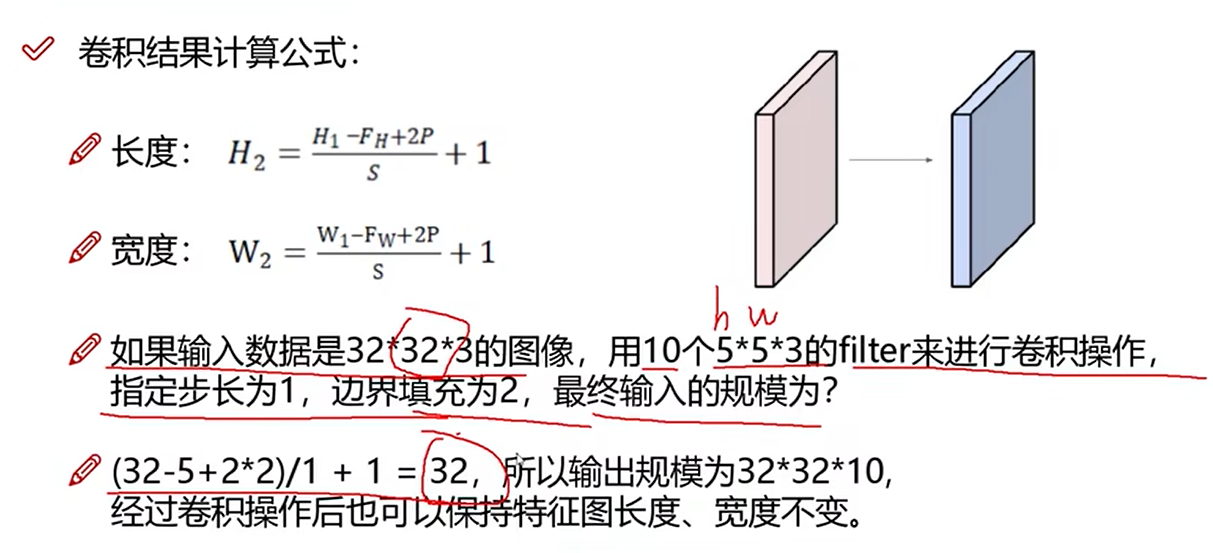
卷积参数共享
每一个区域选用相同的卷积核,从而减少参数个数。