Deep Learning 2
20 池化层的作用
起压缩作用
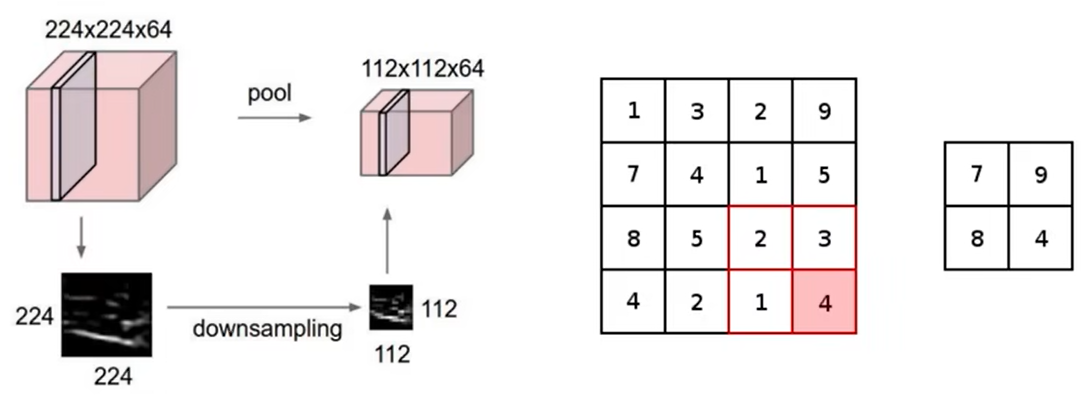
最大池化
h和w会变,通道数c不会变。
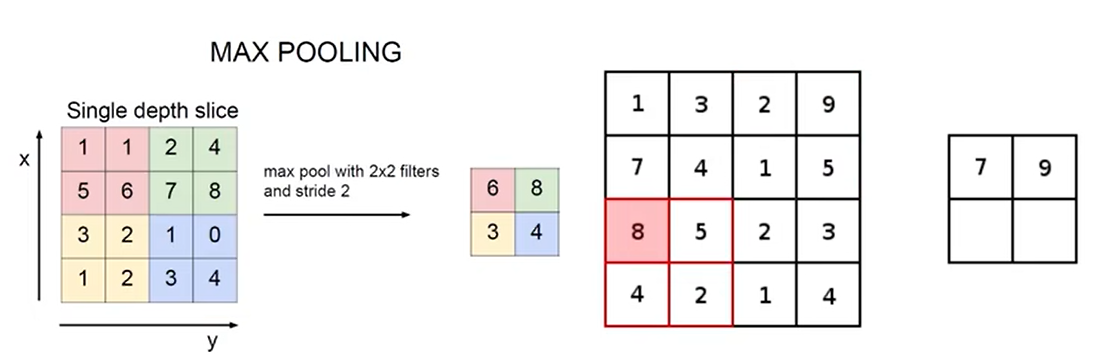
21 整体网络架构
每个卷积层后都有激活函数RELU,池化层不需要。多次卷积后一次池化。
最后要先将三维的特征图展平成特征向量,再用全连接层FC分类。

只有带参数才能称为层,卷积层和全连接层属于层。激活函数和池化层不算。
特征图变化
转换:三维转换成一维向量
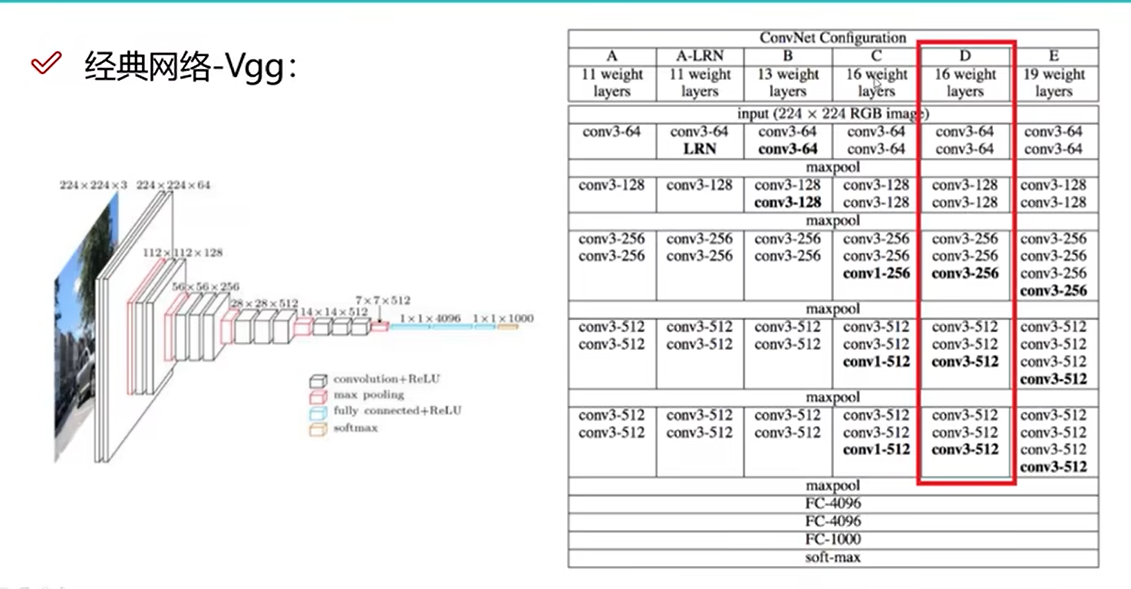
22 VGG网络架构
经典网络-Alexnet
5层卷积,3层全连接

VGG
- 卷积核大小都是3×3。
- 16层或19层常用。
- 每一次池化层后卷积核个数翻倍,弥补池化损失。
23 残差网络Resnet
经典网络-Resnet
当做特征提取,而不是分类
如果某一层效果不好,会把该层的权重改为0,H(x)=x。
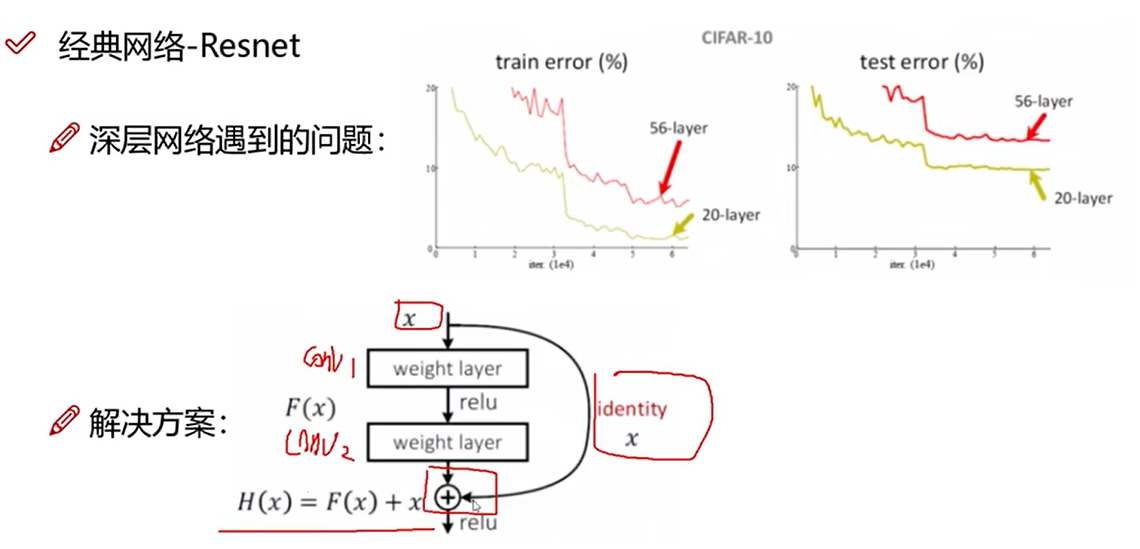
效果
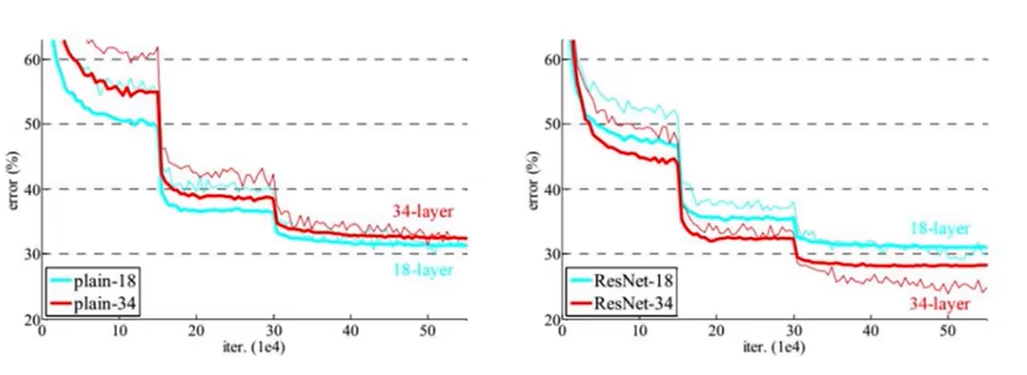
24 感受野的作用
感受野
每一层的输出能感受前一个输入。感受野是最后一层能感受到最初输入的范围。下图第二层的一块先感受到第一个卷积层3×3范围,后者是对最初5×5范围卷积得到,所以最后一层能感受到最初输入的范围是5×5。
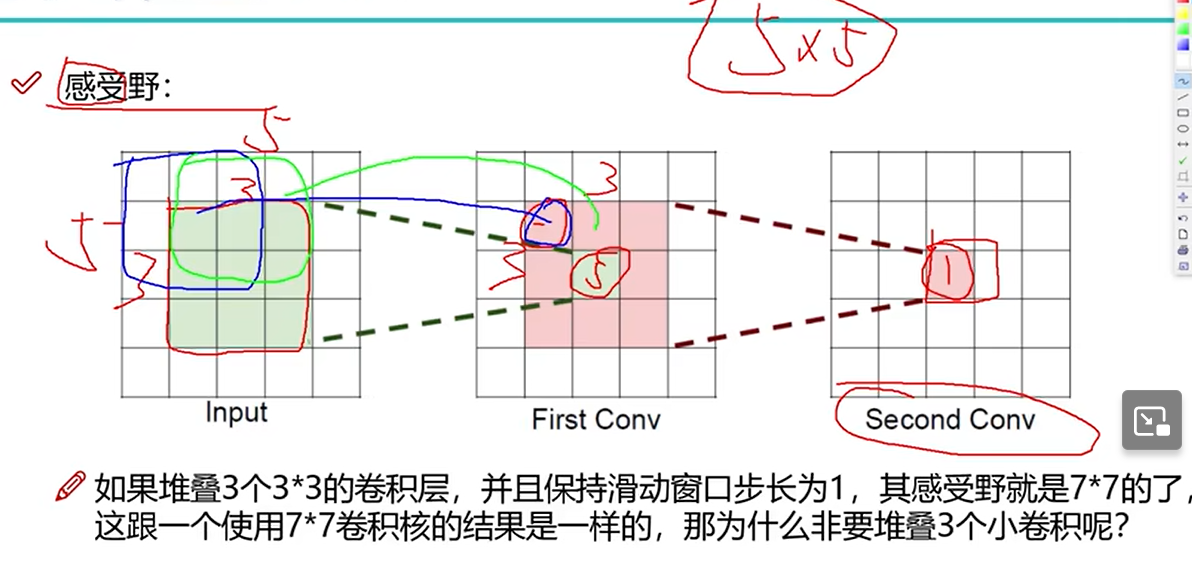
感受野越大越好,说明一小块能代表原始数据大块特征。
堆叠3个小的卷积核原因

25 RNN网络架构解读
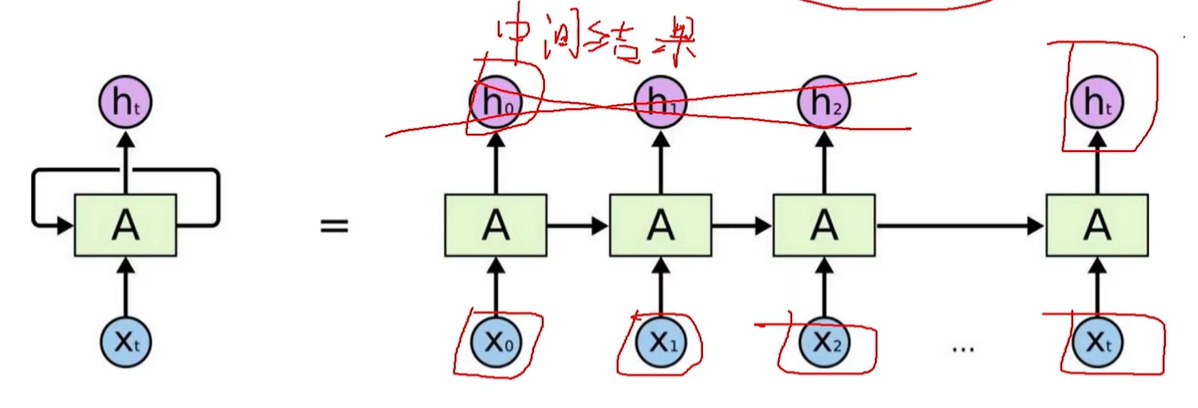
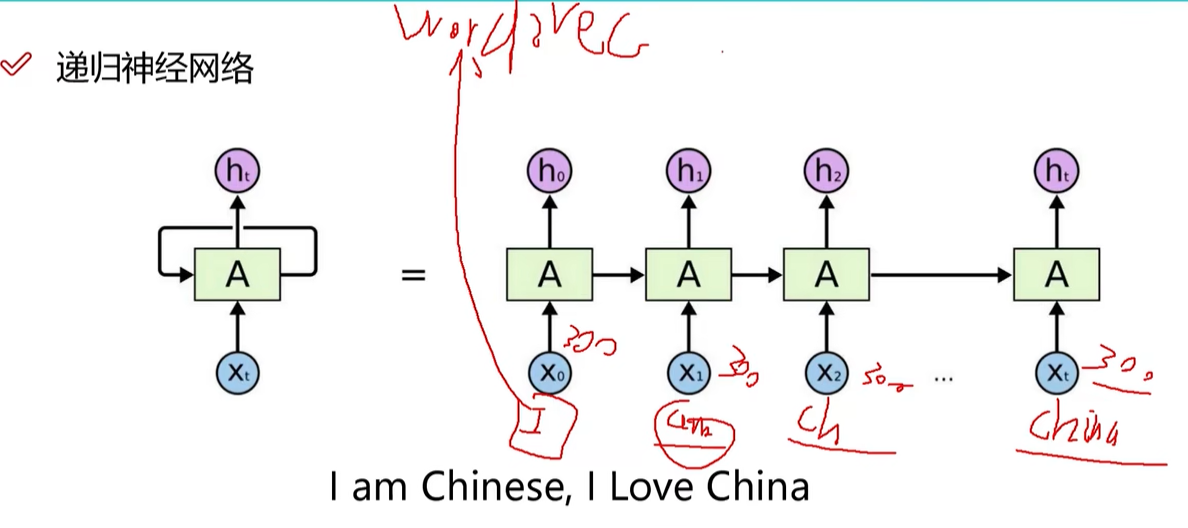
递归神经网络
能够处理时间序列。前一个时刻输入产生的特征会对后一个时刻的输入产生影响。前一个输入的中间结果保留,参与下一个输入的计算。
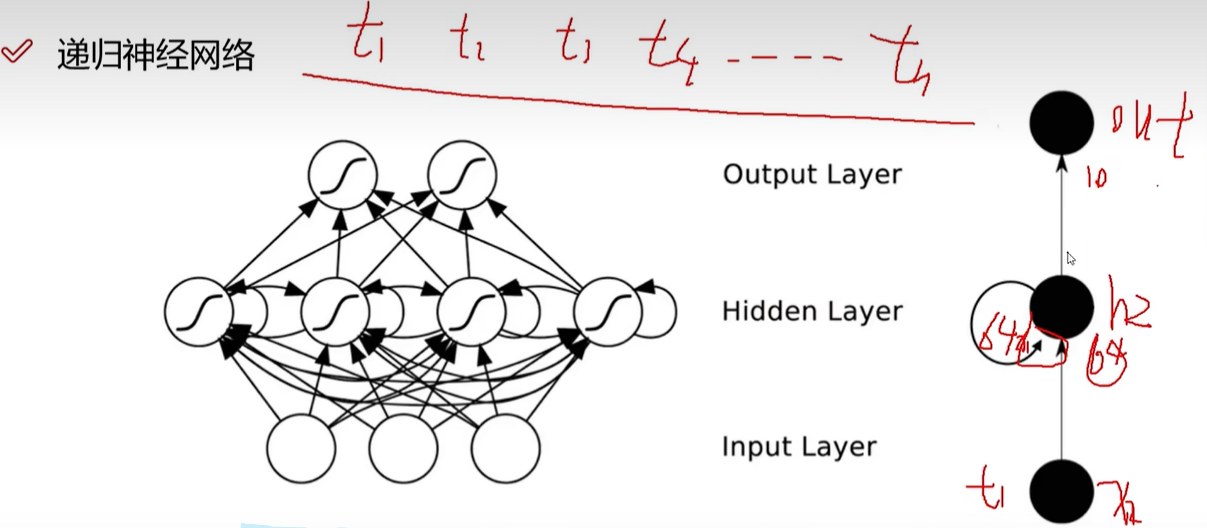
常用于自然语言处理。
举例
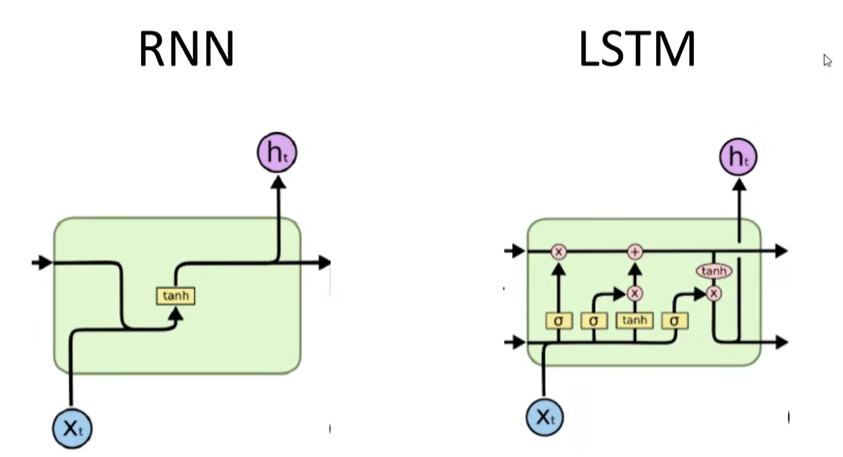
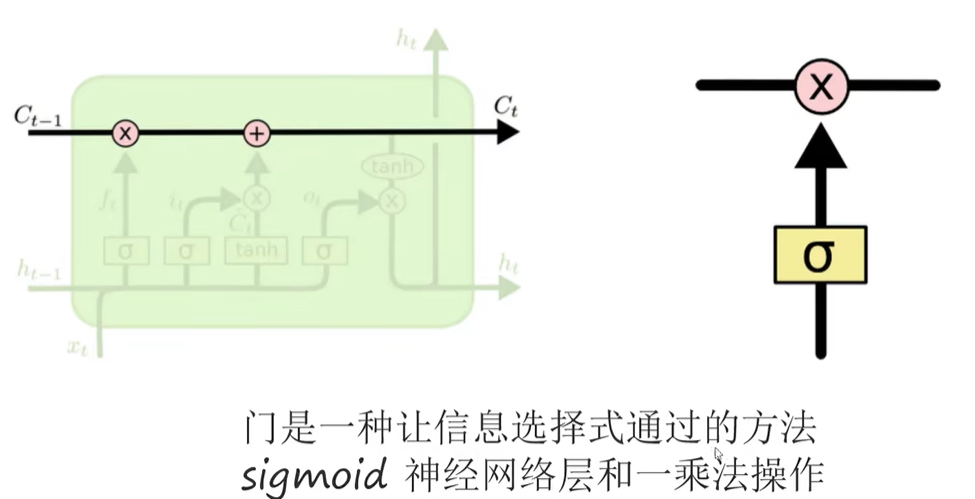
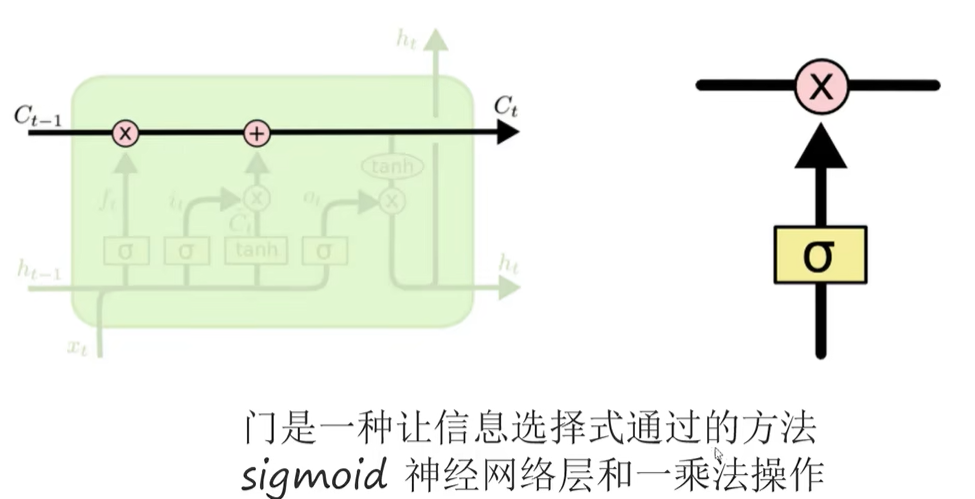
LSTM网络
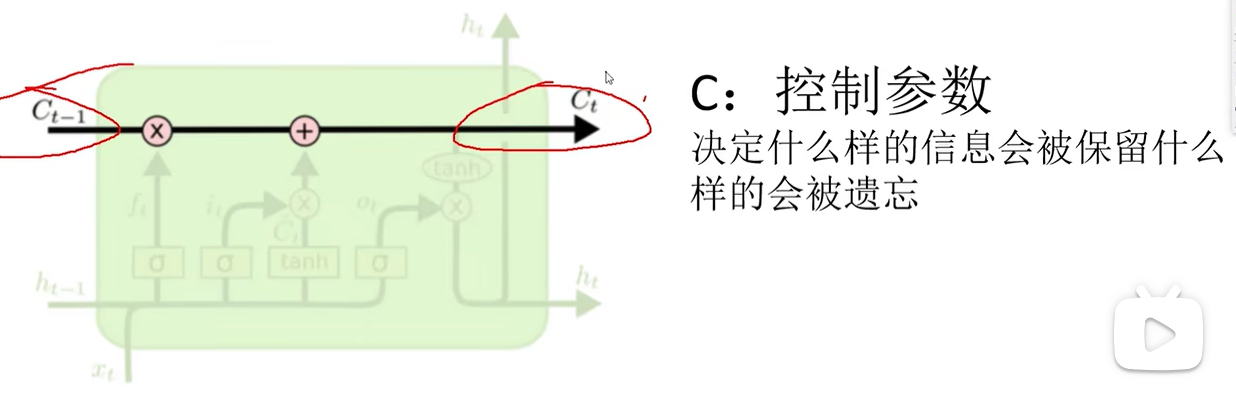
决定丢弃信息
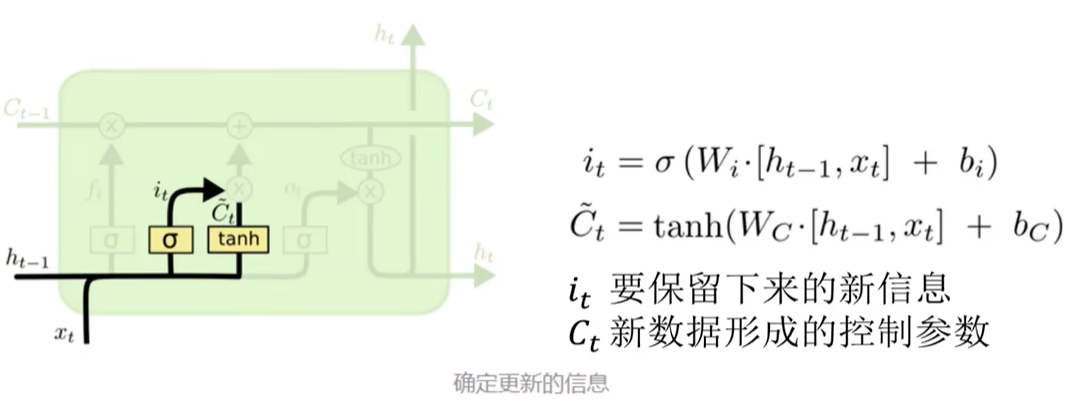
确定更新的信息
26 词向量模型Word2Vec通俗解释
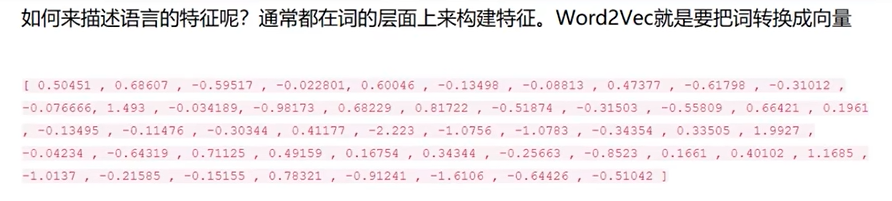
文本向量化

27 模型整体框架

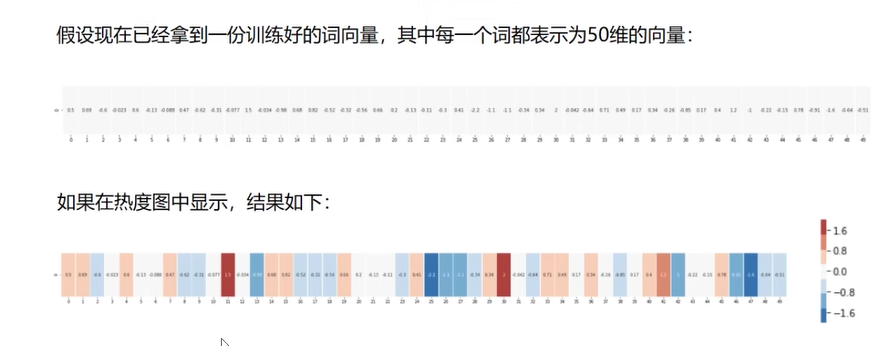
Word2Vec把词转换成向量
- 向量的维度指坐标个数。
- 二维张量可以表示为 [[1, 2, 3], [4, 5, 6]],其中有两个维度,每个维度包含三个元素。所以该张量的维度是 (2, 3)。
热度图

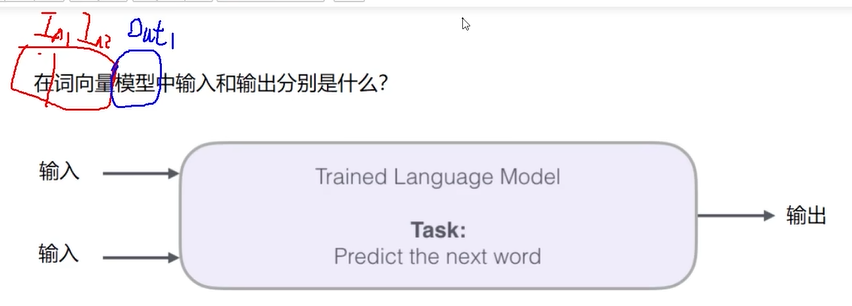
词向量的输入和输出
能够根据输入预测下一个词(输出)
输出显示每个词的概率
embeddings
根据输入从语料库中找到词向量。
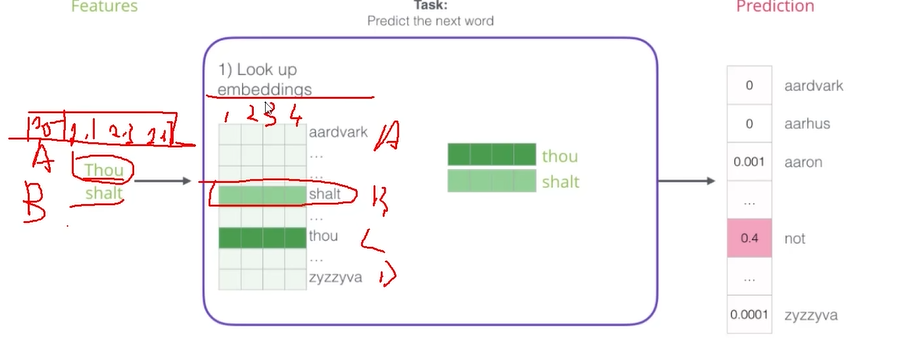
语料库开始随机初始化,每一轮训练会更新。
28 训练数据构建
数据从哪里来
词语含义可以跨文本(新闻,小说)
构建训练数据
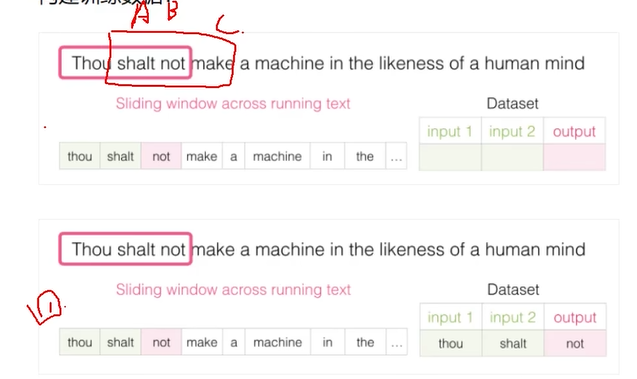
滑动窗口
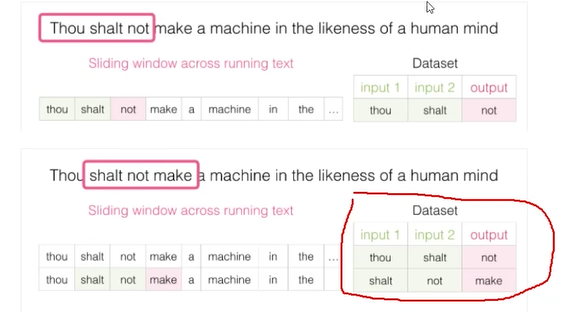
29 CBOW与Skipgram模型
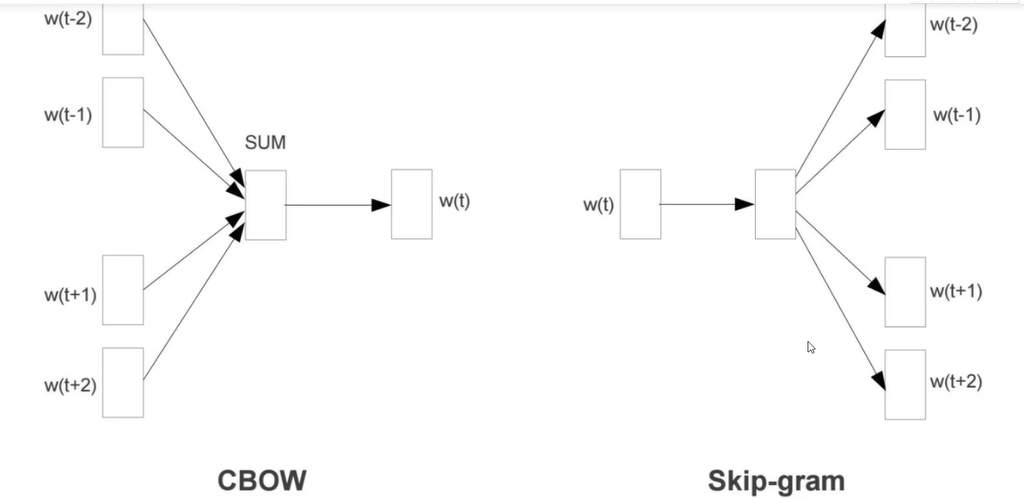
CBOW
输入上下文,前后夹中间

Skipgram
通过中间词预测上下文
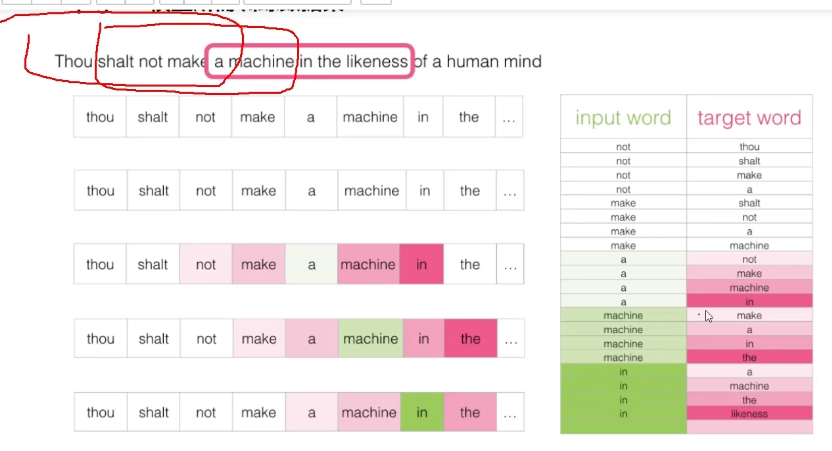
Skip-gram模型所需训练数据集

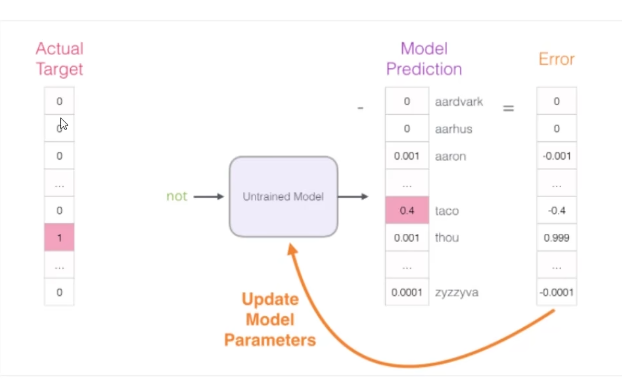
如何进行训练
结果太多解决方法
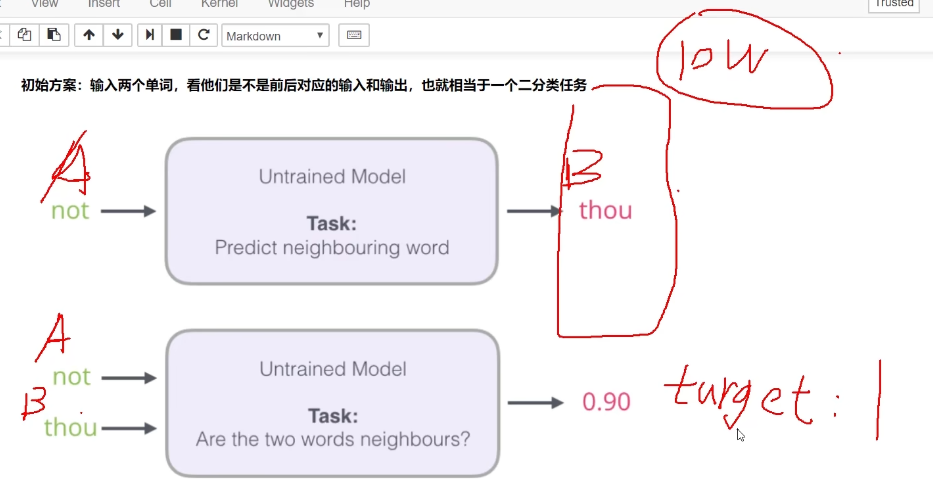
输出加入到输入,希望标签是1或0,最后一层变为二分类

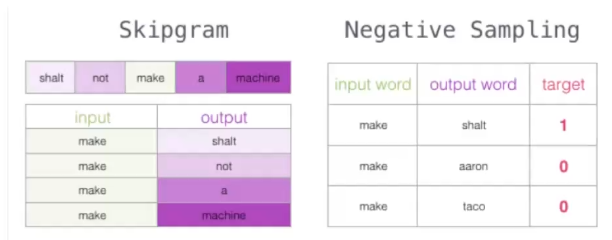
30 负采样方案
改进方案
人为添加标签为0的词,称为负样本。推荐5个

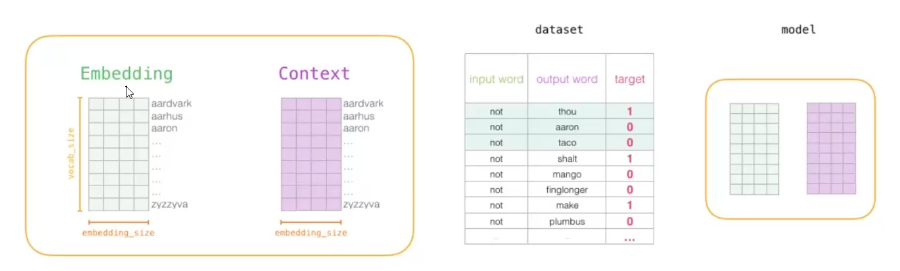
词向量训练过程
初始化词向量矩阵
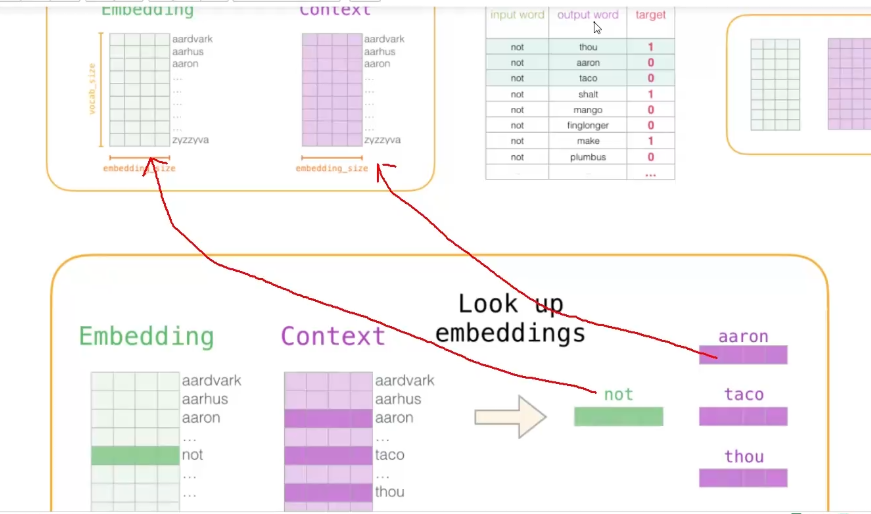
反向传播更新

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 TechNotes!
评论