PyTorch_Practice_3
11 Advanced CNN
GooLeNet
减少代码冗余:函数/类
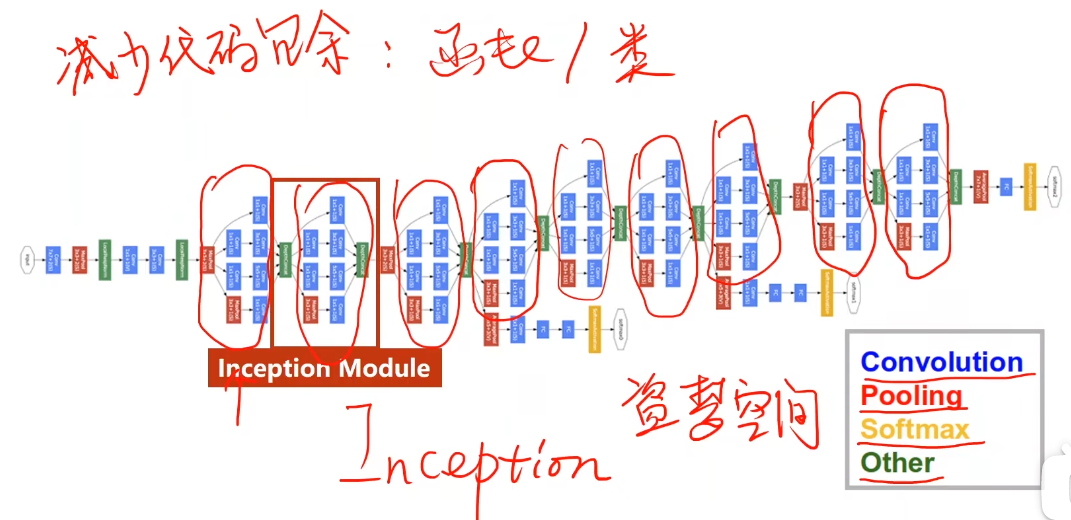
Inception Module
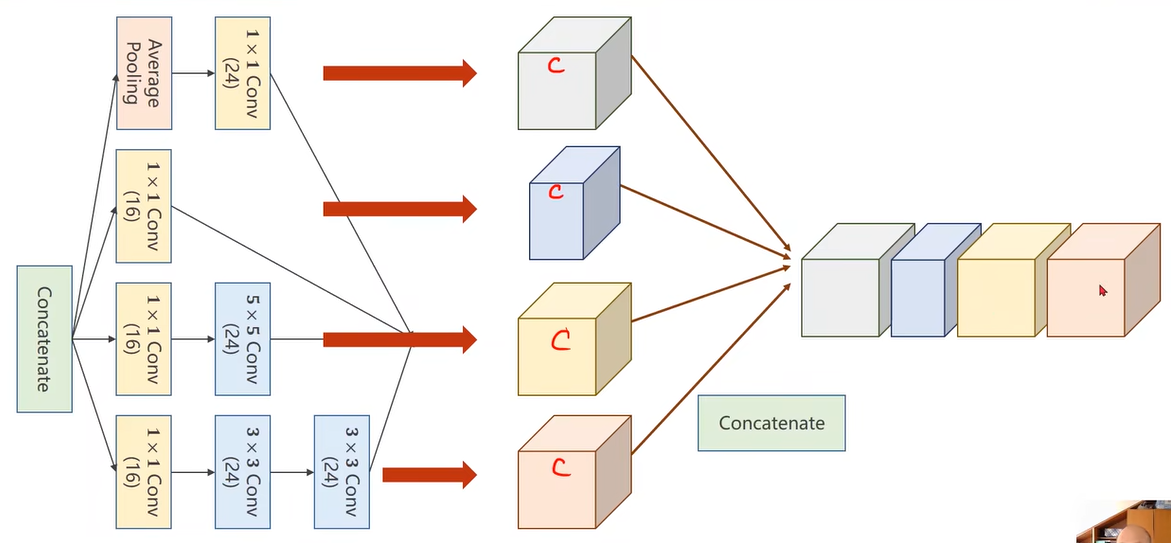
Concatenate:拼接张量
每种方式都使用,通过训练找到最优组合,调整权重。
Average Polling平均池化
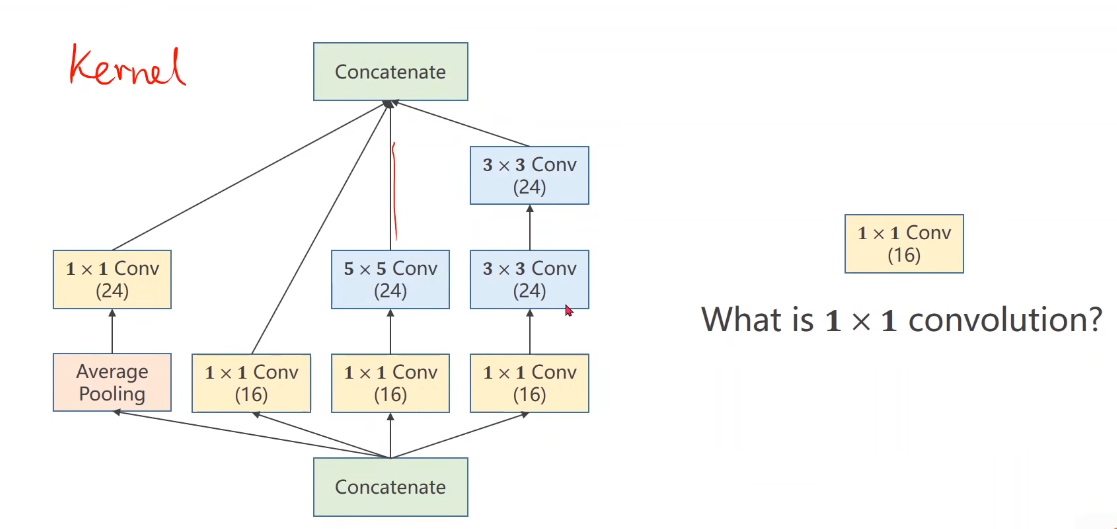
What is 1×1 convolution?
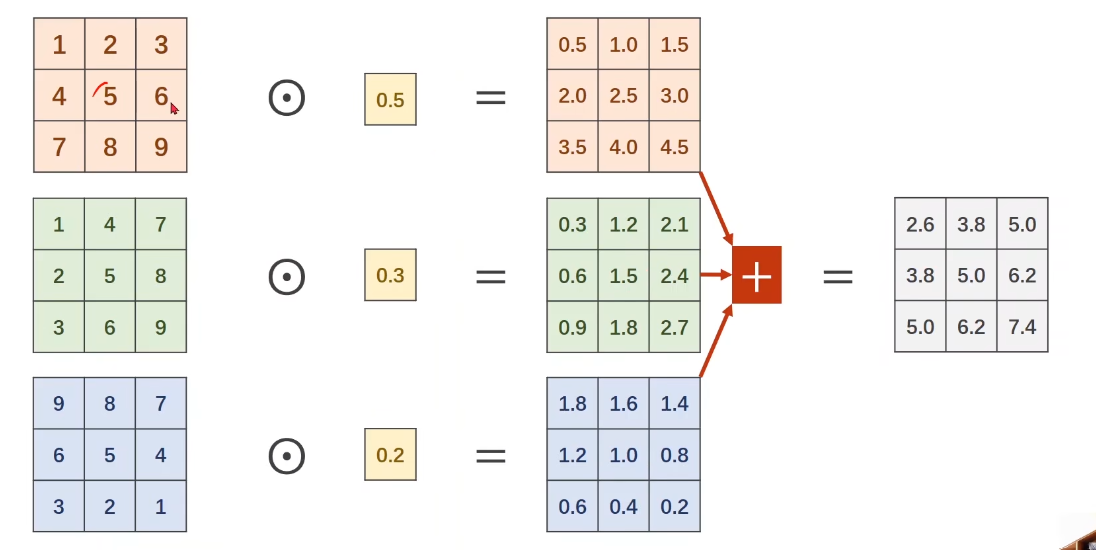
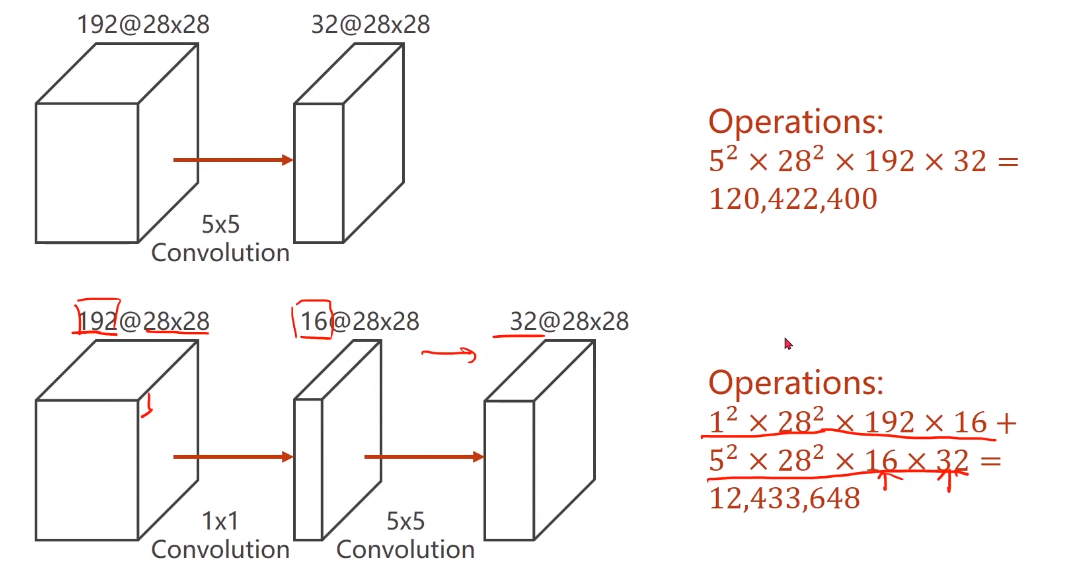
可以改变通道数量,降低运算量
Implementation of Inception Module
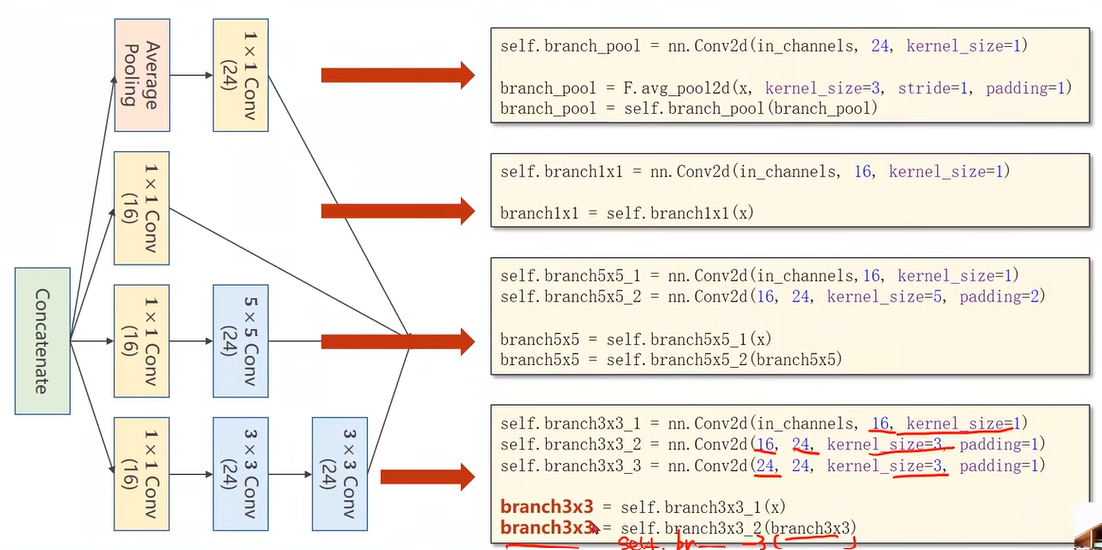
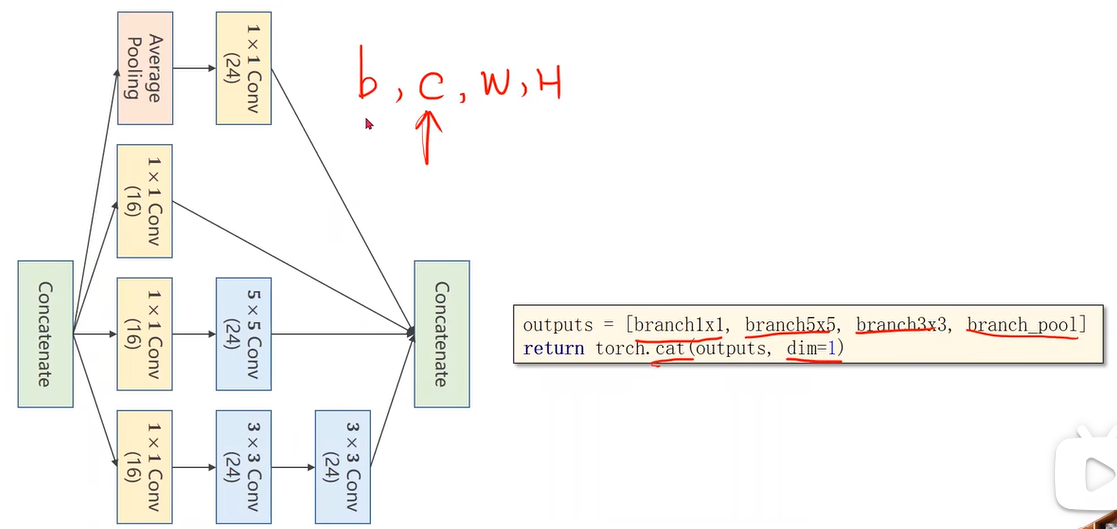
沿着通道维度拼接
dim=1因为张量维度顺序是B,C,W,H
1 | |
1 | |
Results of using Incuption Module

Can we stack layers to go deeper?
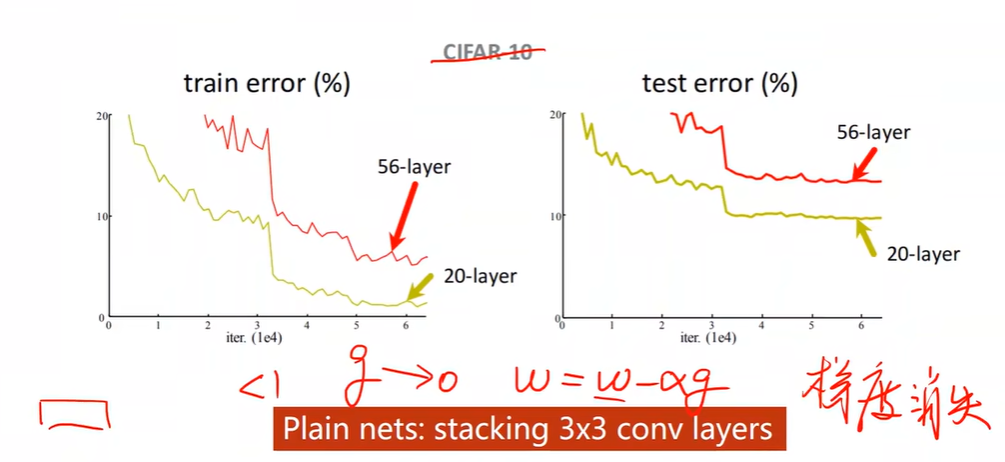
Deep Residual Learning 深度残差学习
增加跳连接,能解决梯度消失问题
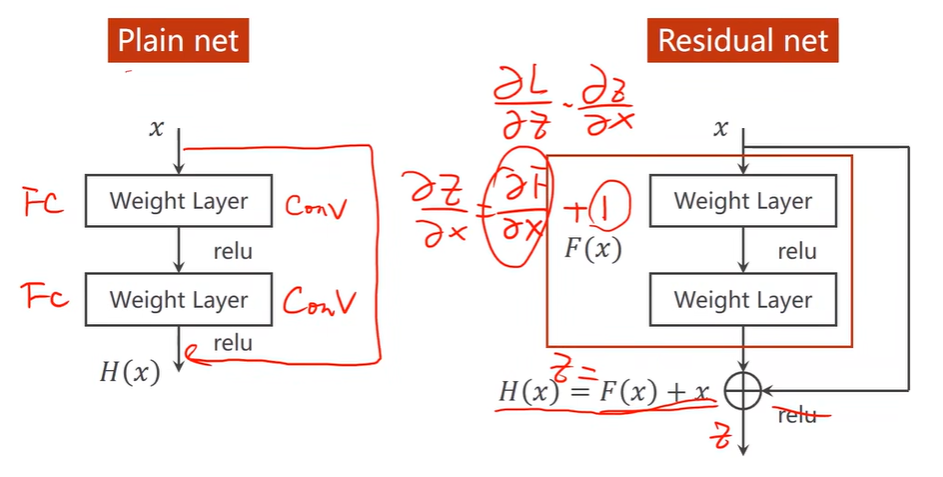
Residual Network
虚线表示输入和输出维度不同,需要特殊处理
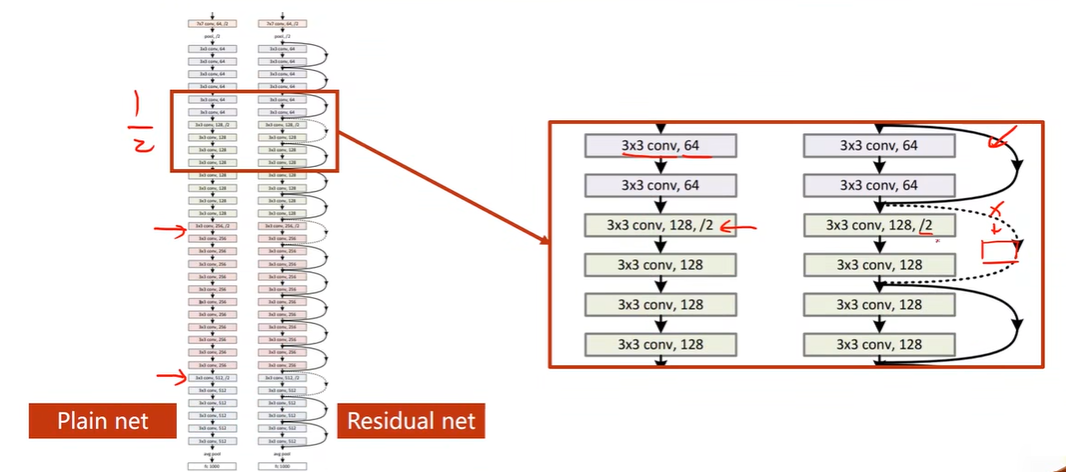
Implementation of Simple Residual Network

1 | |
1 | |
Results
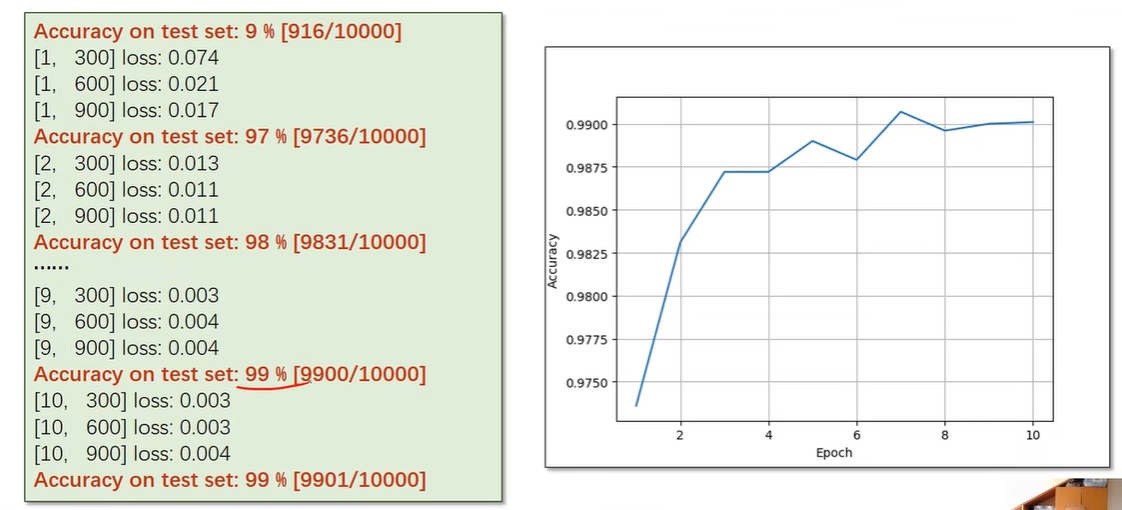
12 Basic RNN
处理序列关系的数据:自然语言处理
Wht is RNNs?
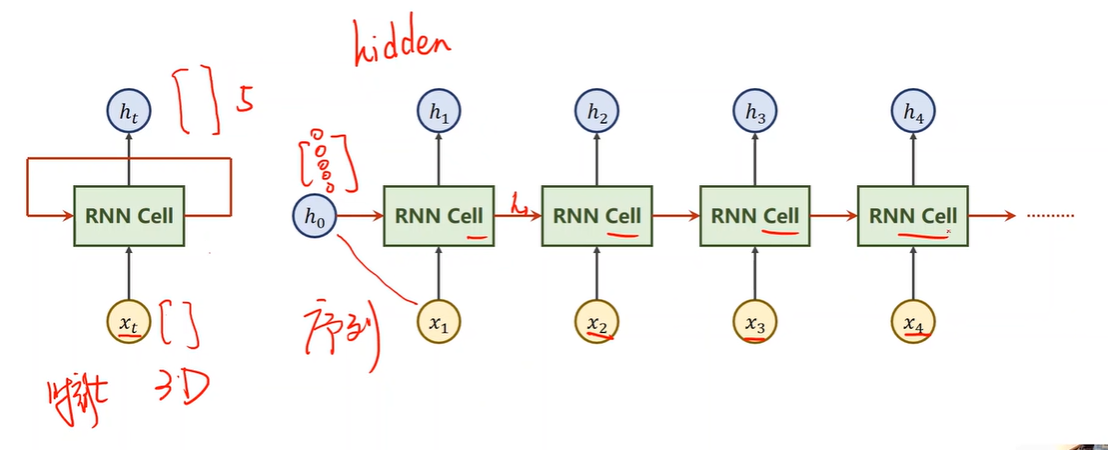
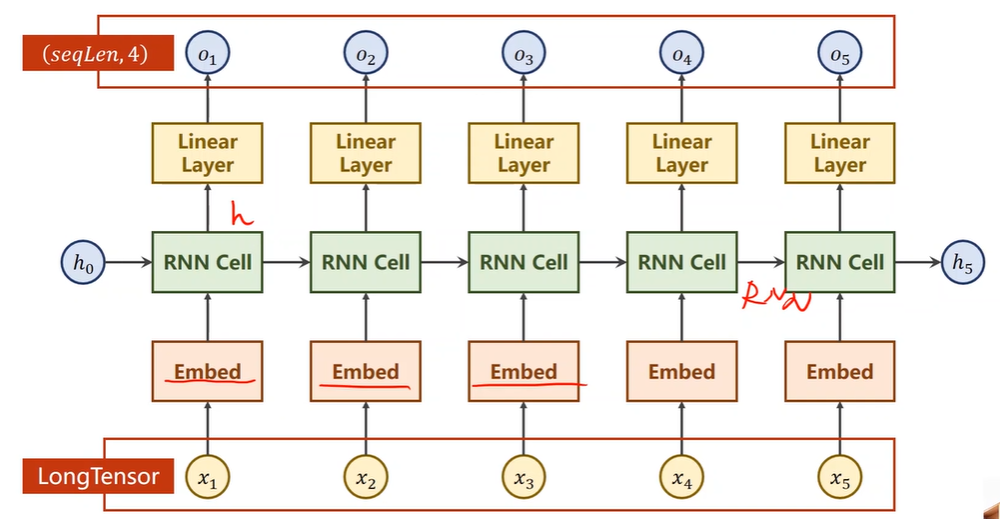
What is RNN Cell?
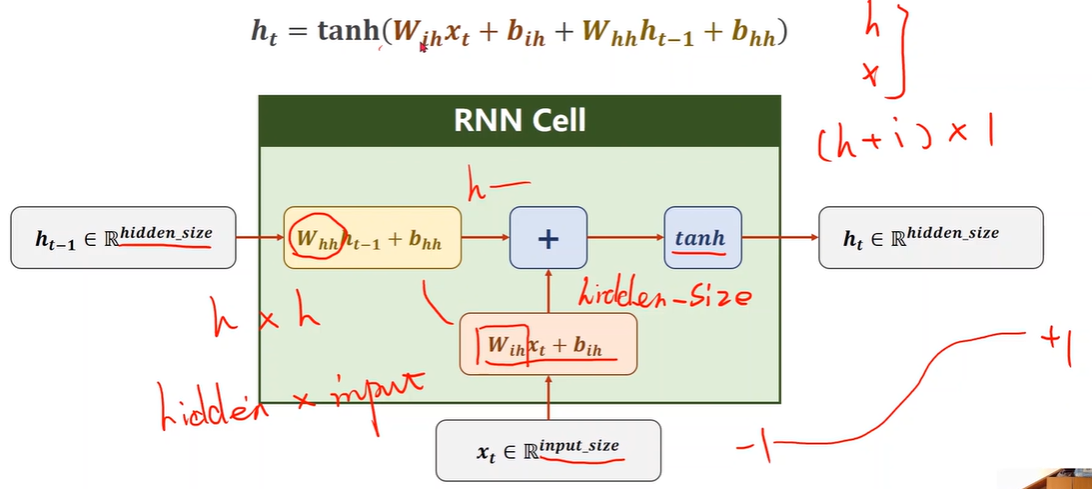
RNN Cell in PyTorch
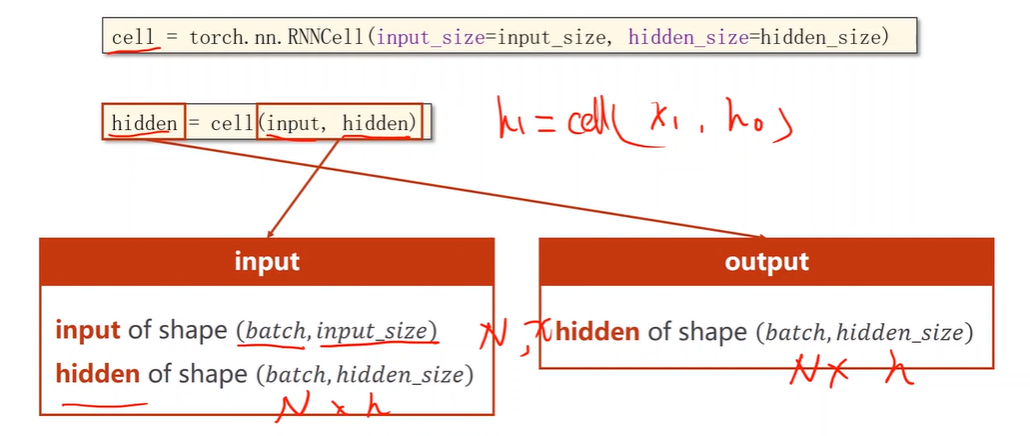
How to use RNNCell

1 | |

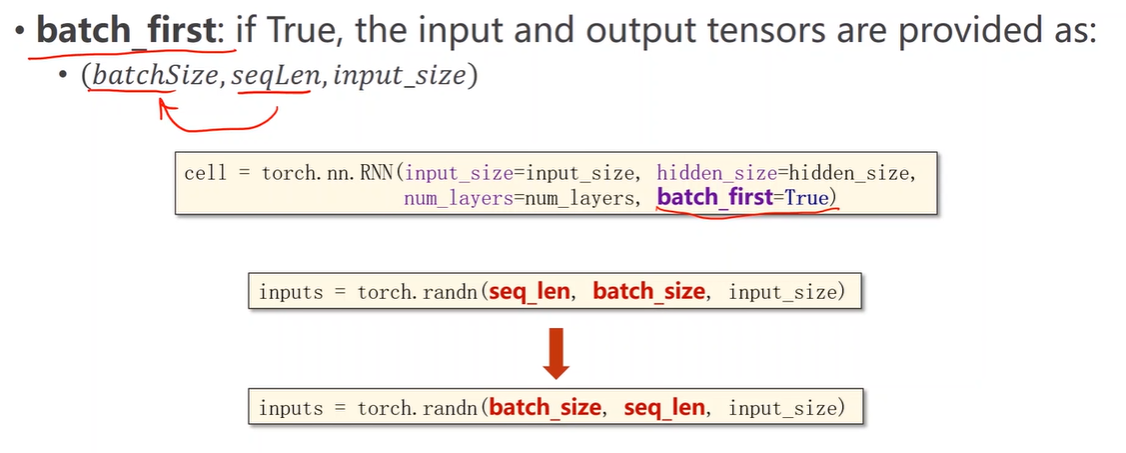
How to use RNN
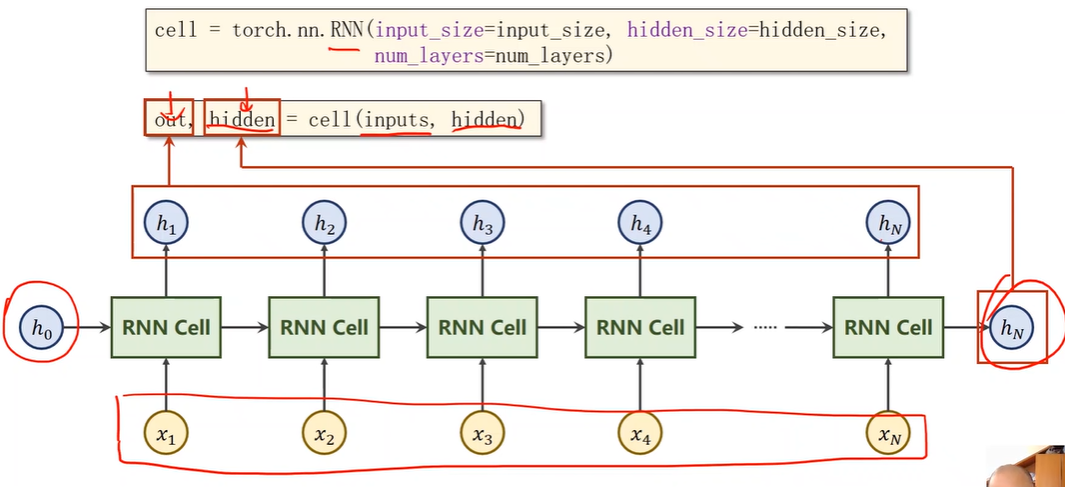


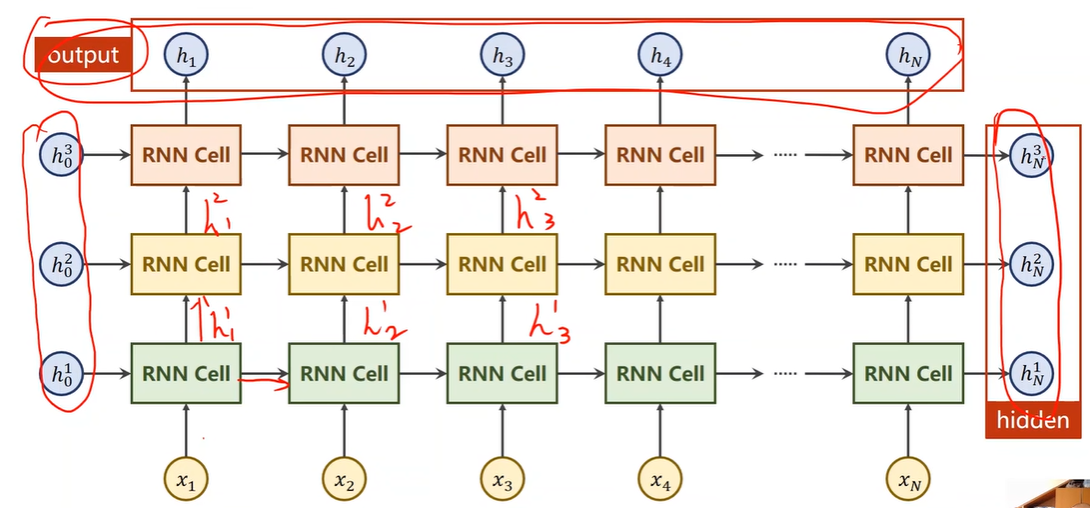
numLayers
RNN的层数,不是RNNCell的个数
1 | |


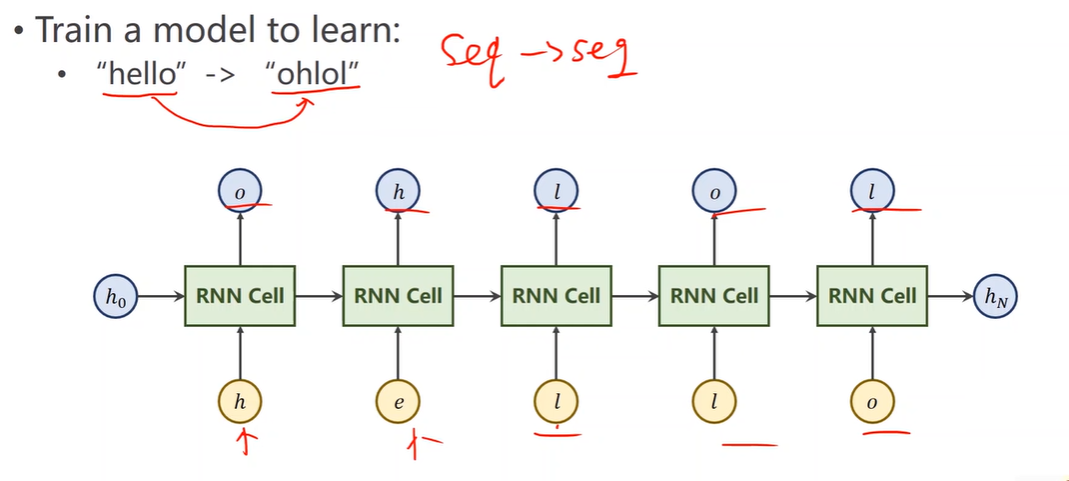
Example: Using RNNCell
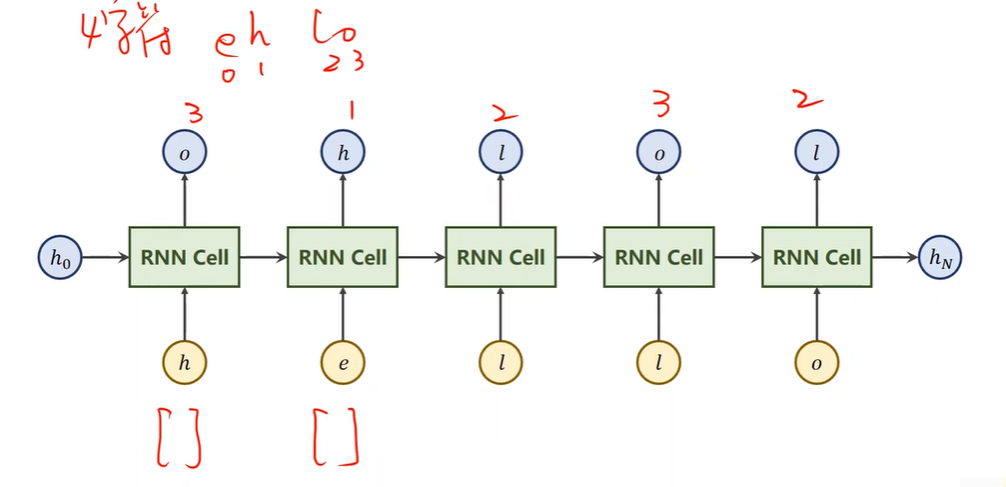
独热向量:One-Hot Vector

分类问题
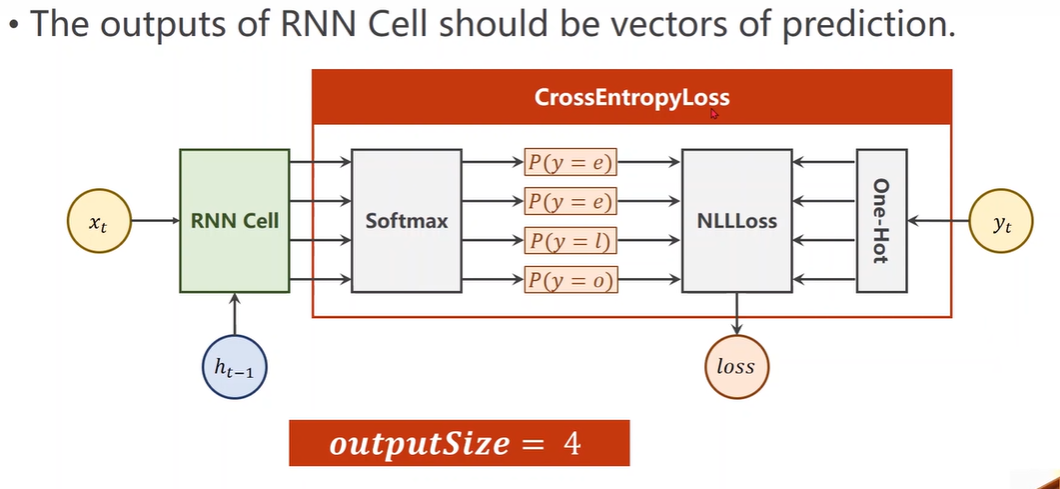
Pramenters
1 | |
Prepare Data
1 | |
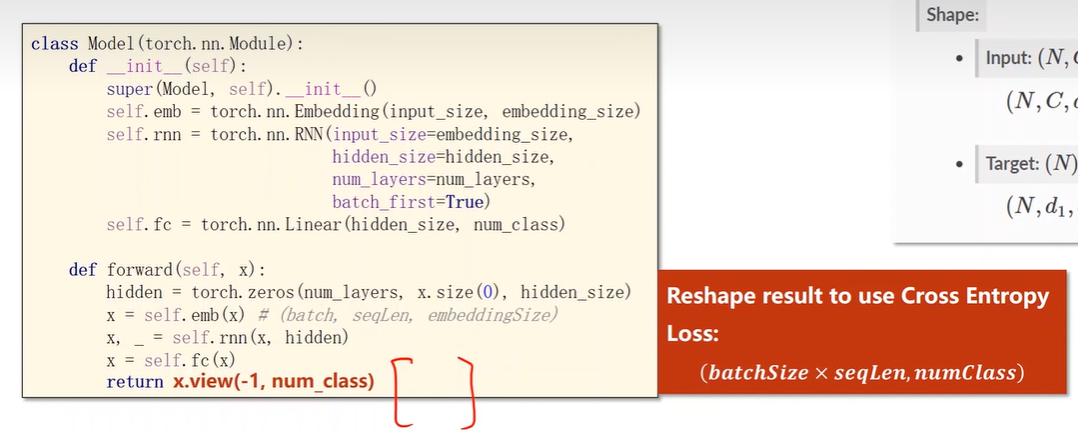
Design Model
1 | |
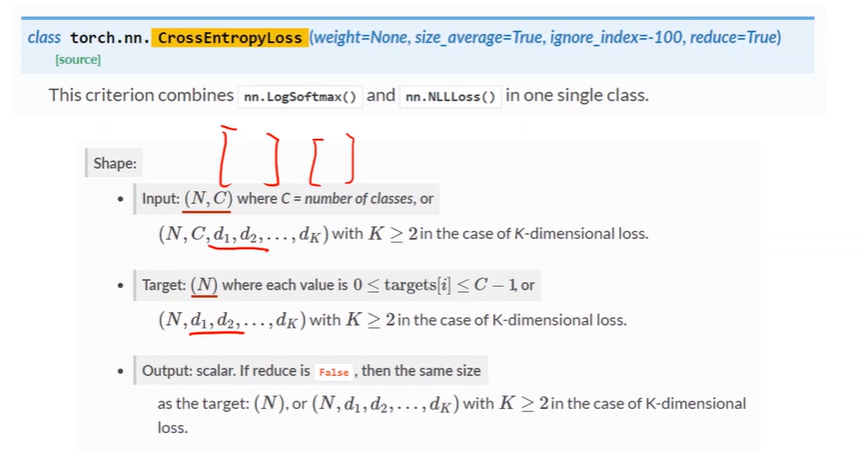
Loss and Optimizer
1 | |
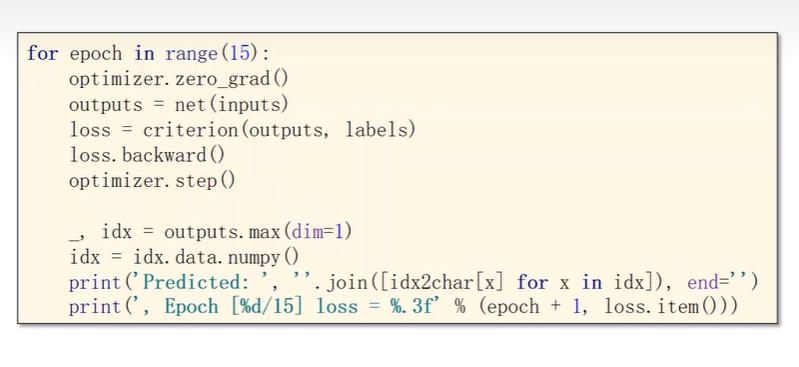
Training Cycle
1 | |
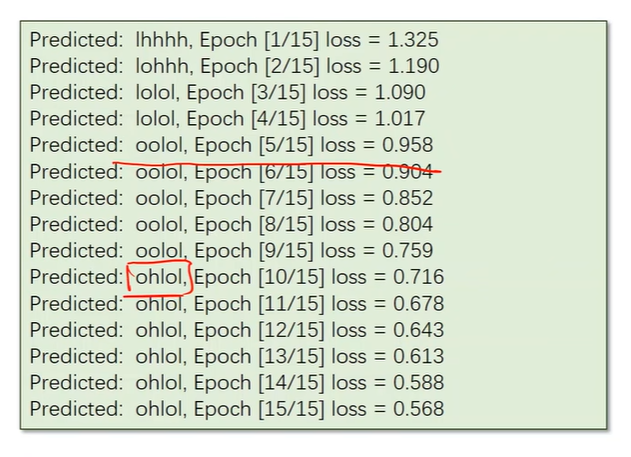
Results

Using Rnn Module
1 | |
Change Model



Change Data


Result
Associate a vector with a word/character
One-hot encoding of words and characters
- The one-hot vectors are high-dimension.
- The one-hot vectors are sparse.
- The one-hot vectors are hardcoded.
Do we have a way to associate a vector with a word/character
with following specification:
- Lower-dimension
- Dense
- Learned from data
A popular and powerful way is called EMBEDDING.
One-hot vs Embedding

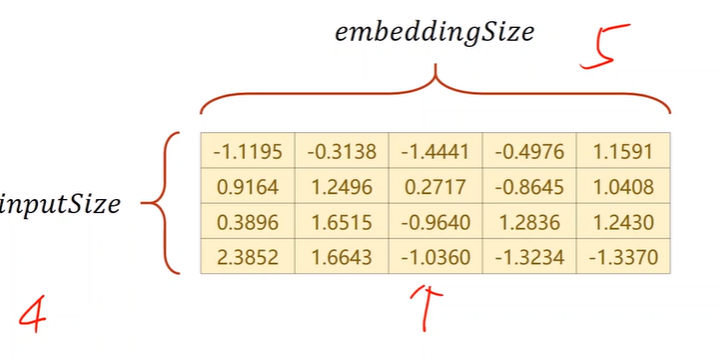
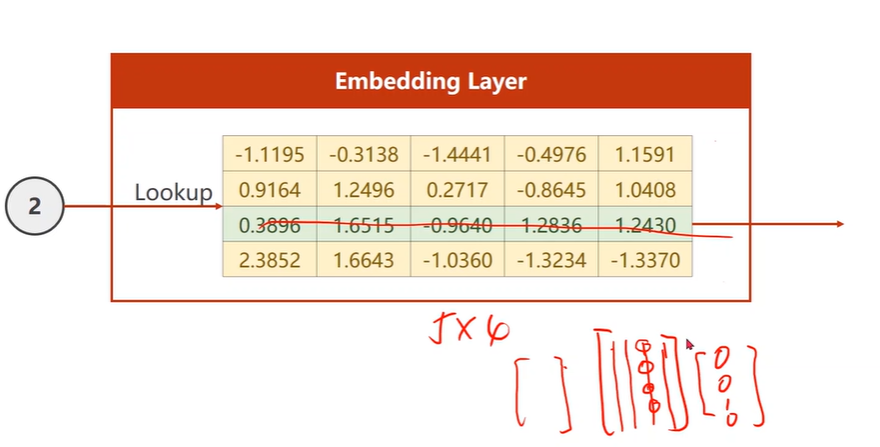
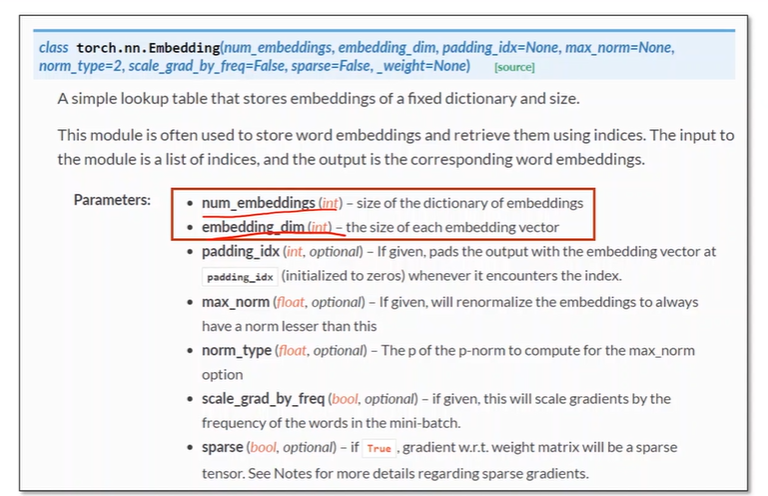
Embedding in Pytorch
Using embedding and linear layer










13 RNN Classifier
Name Claffication

Our Model
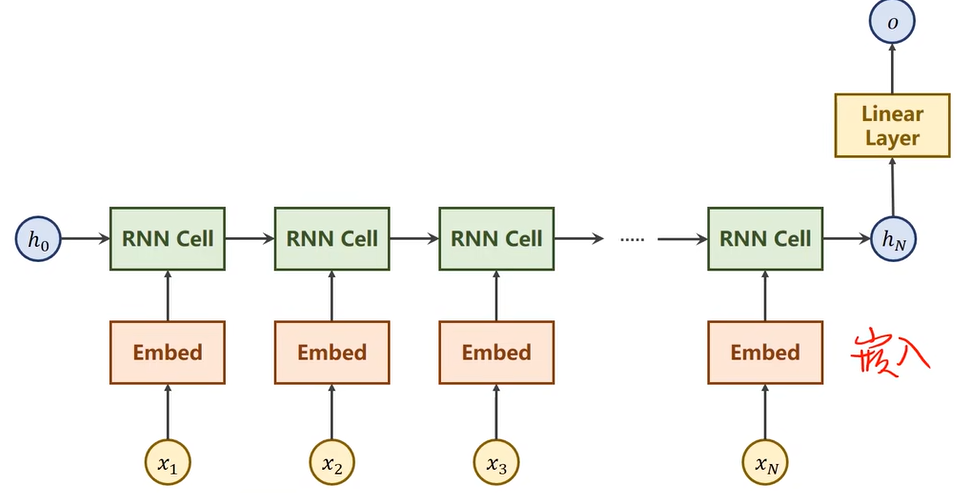

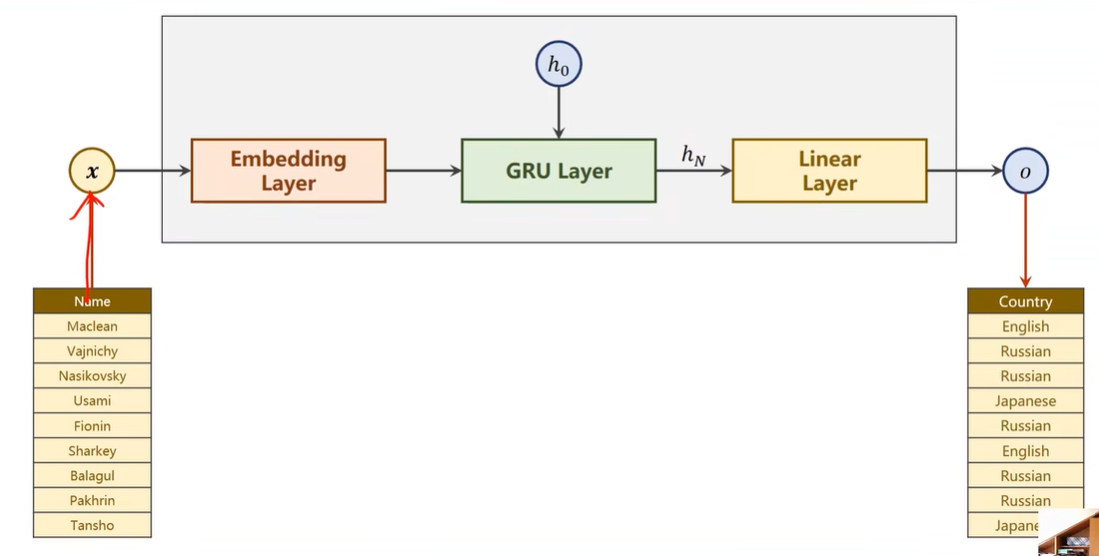
Implementation
Main Cycle
1 | |
Preparing Data
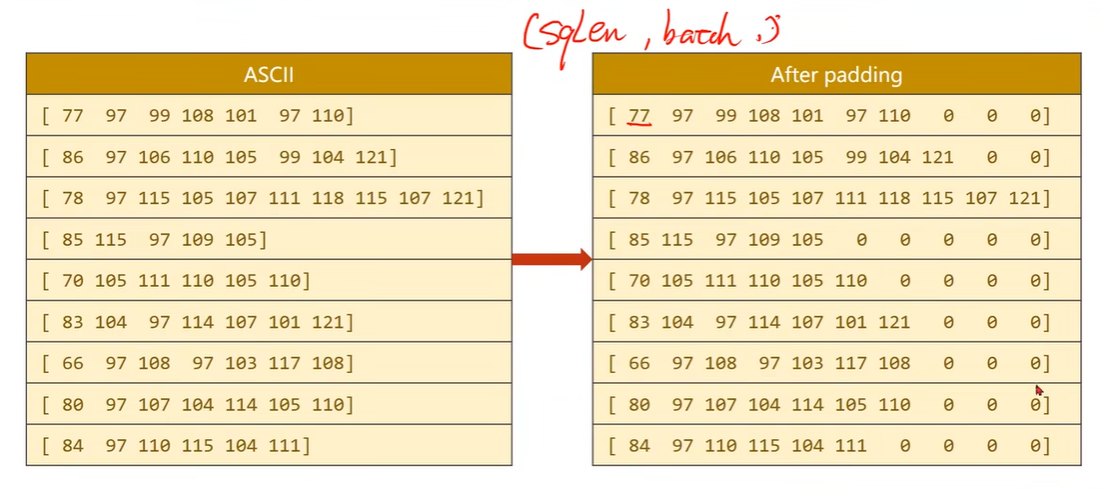
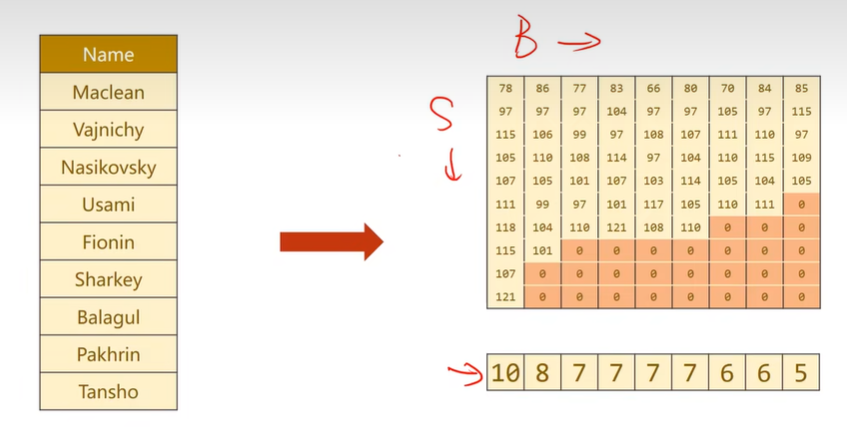
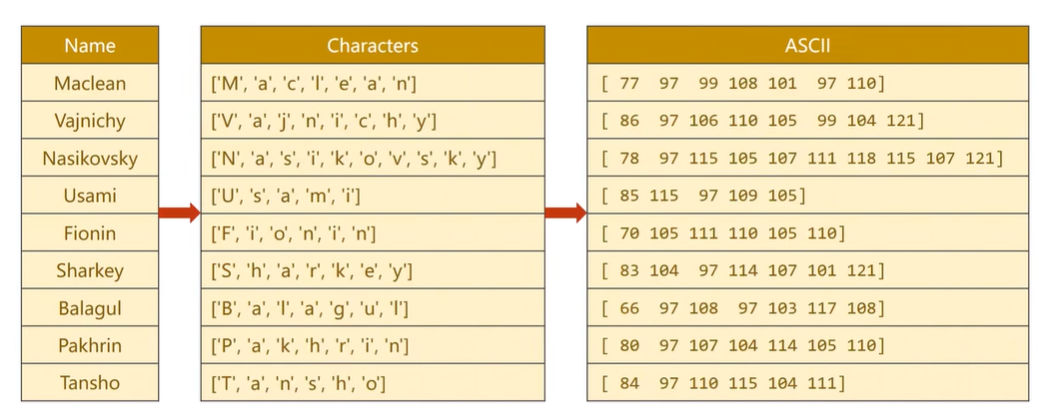
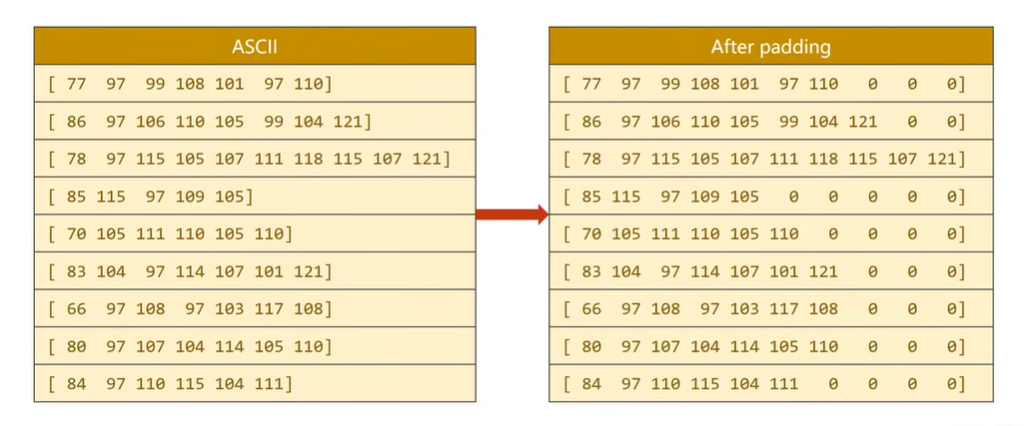
将字符串转换成列表,求每个字符对应的ASCII值

padding:使得字符的长度对齐,方便构成张量
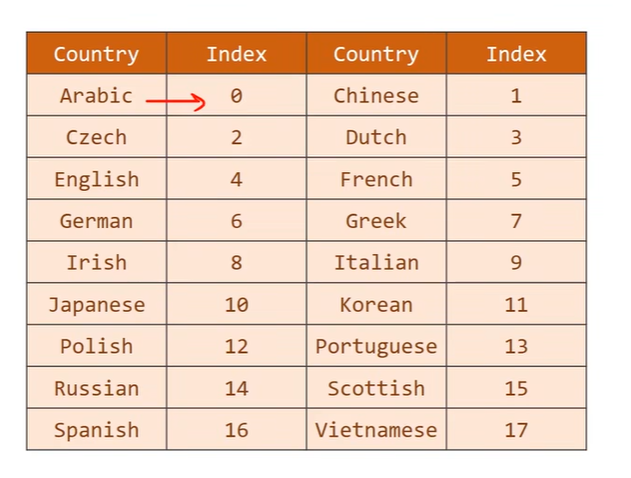
将国家名宇索引对应
1 | |
1 | |
1 | |
1 | |
Model Design
1 | |
Bi-direction RNN/LSTM/GRU
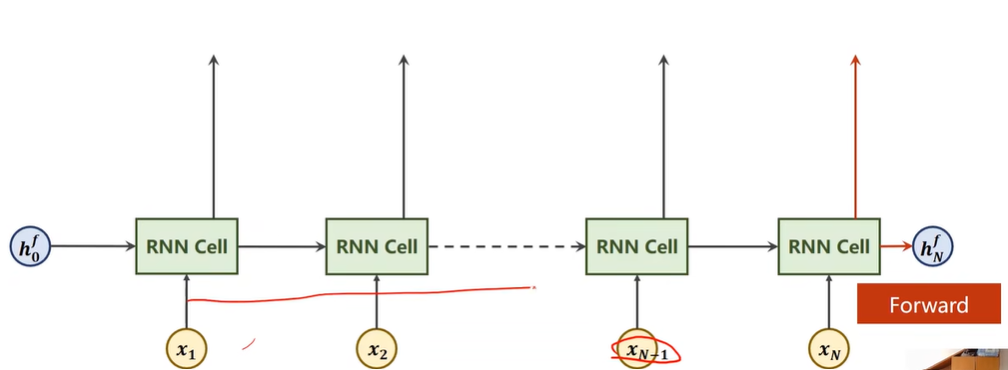
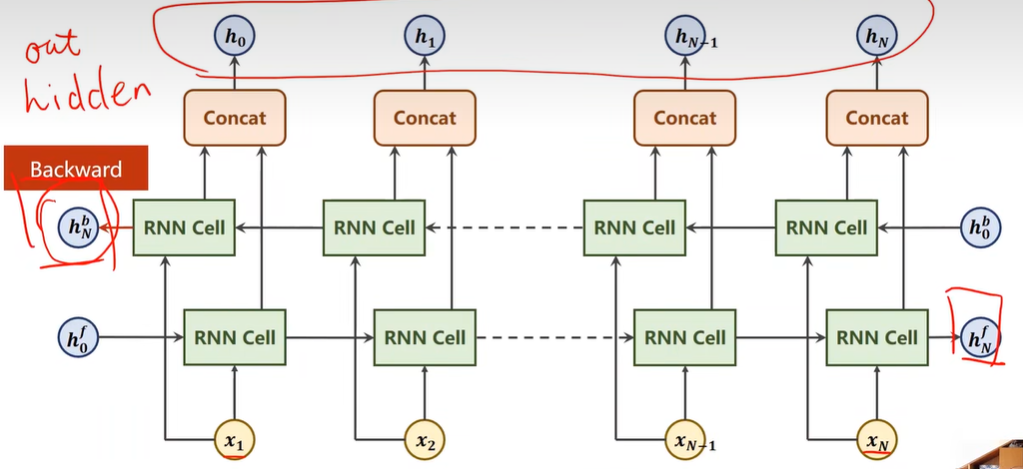
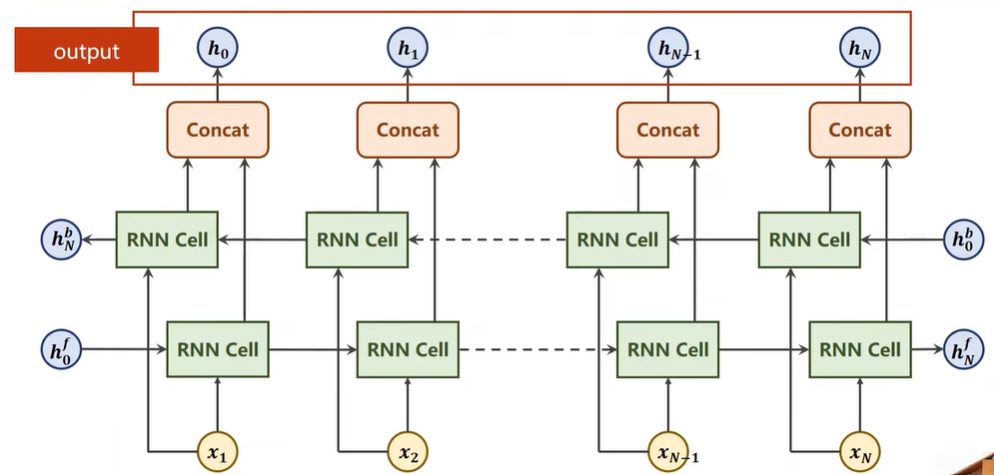
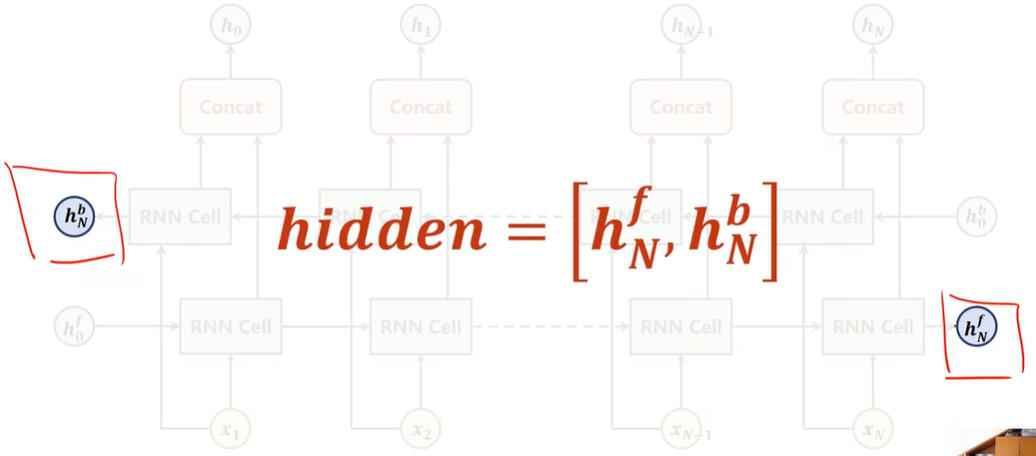
1 | |
pack_padded_sequence(embedding, seq_lengths):
先根据序列长度排序,再只放非0的序列
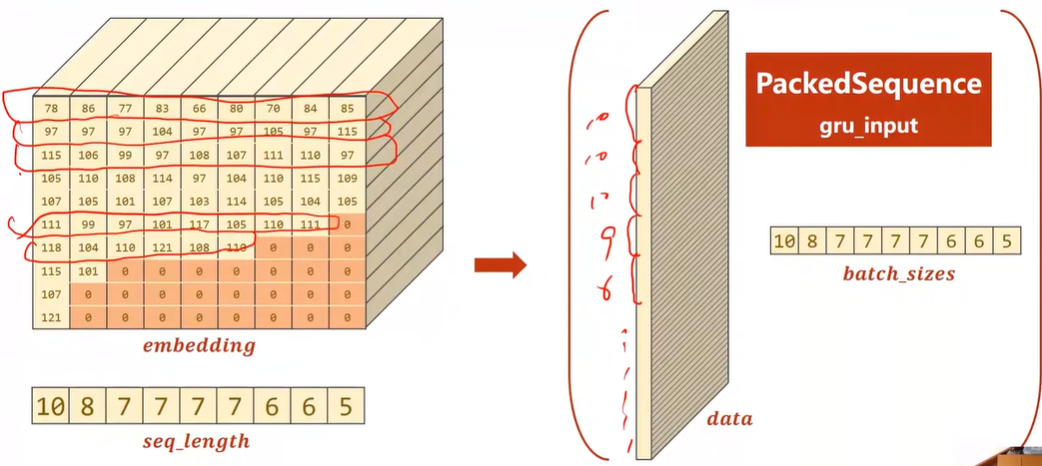
Convert name to tensor
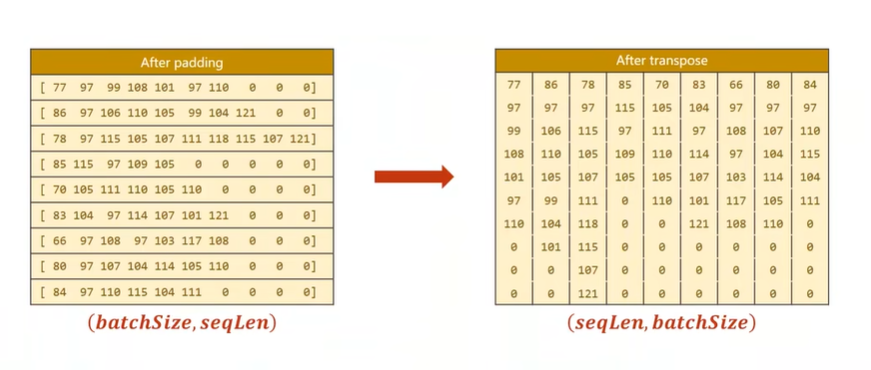

1 | |
One Epoch Training

Testing

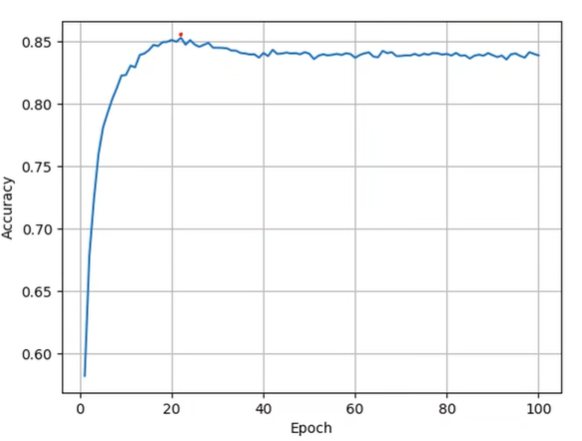
Result
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 TechNotes!
评论