PyTorch深度学习快速入门教程
1 PyTorch 环境配置
Anaconda 安装
显卡配置(驱动+CUDA Toolkit)
有序地管理环境
初始环境:base
切换环境使用不同的pytorch版本
1 | |

1 | |
Pytorch安装
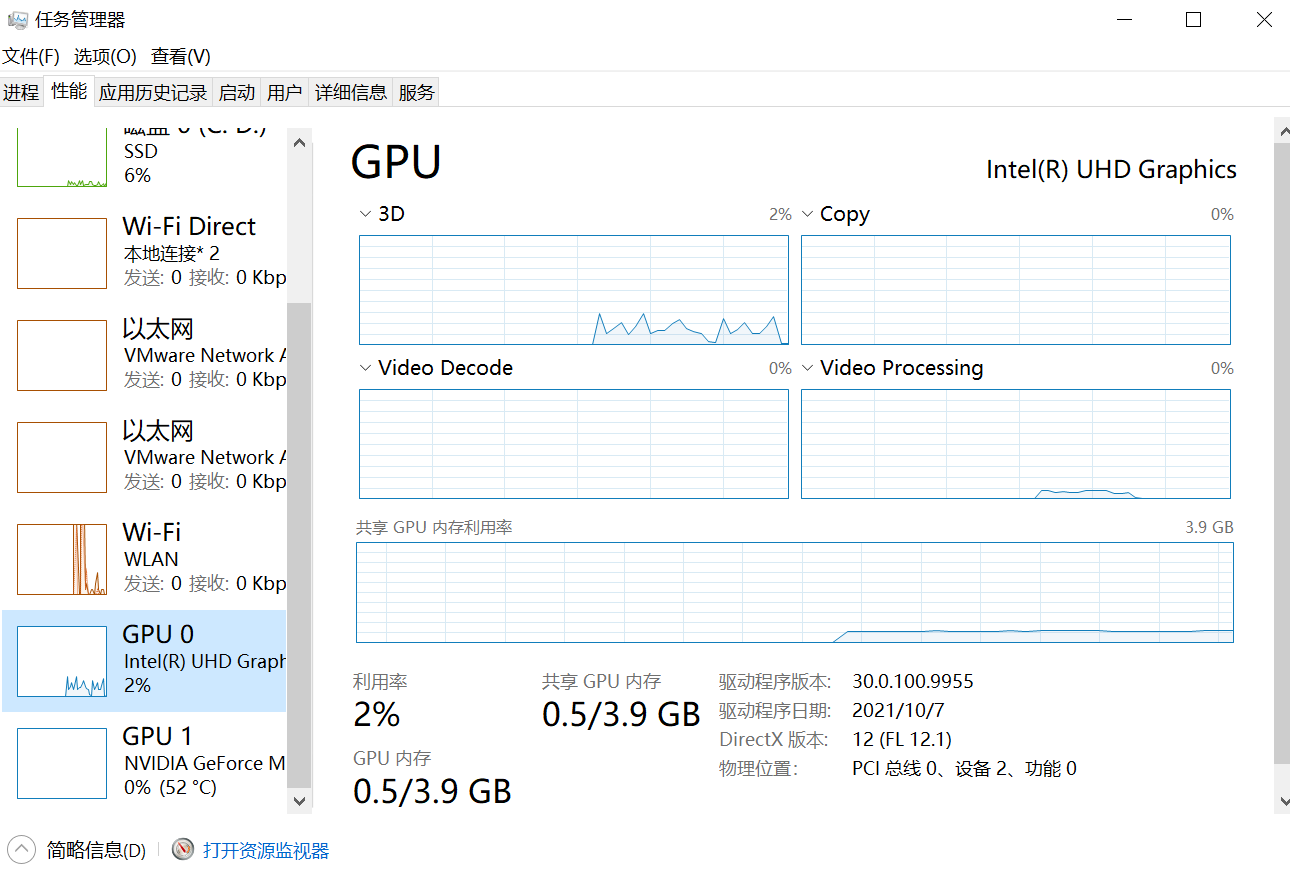
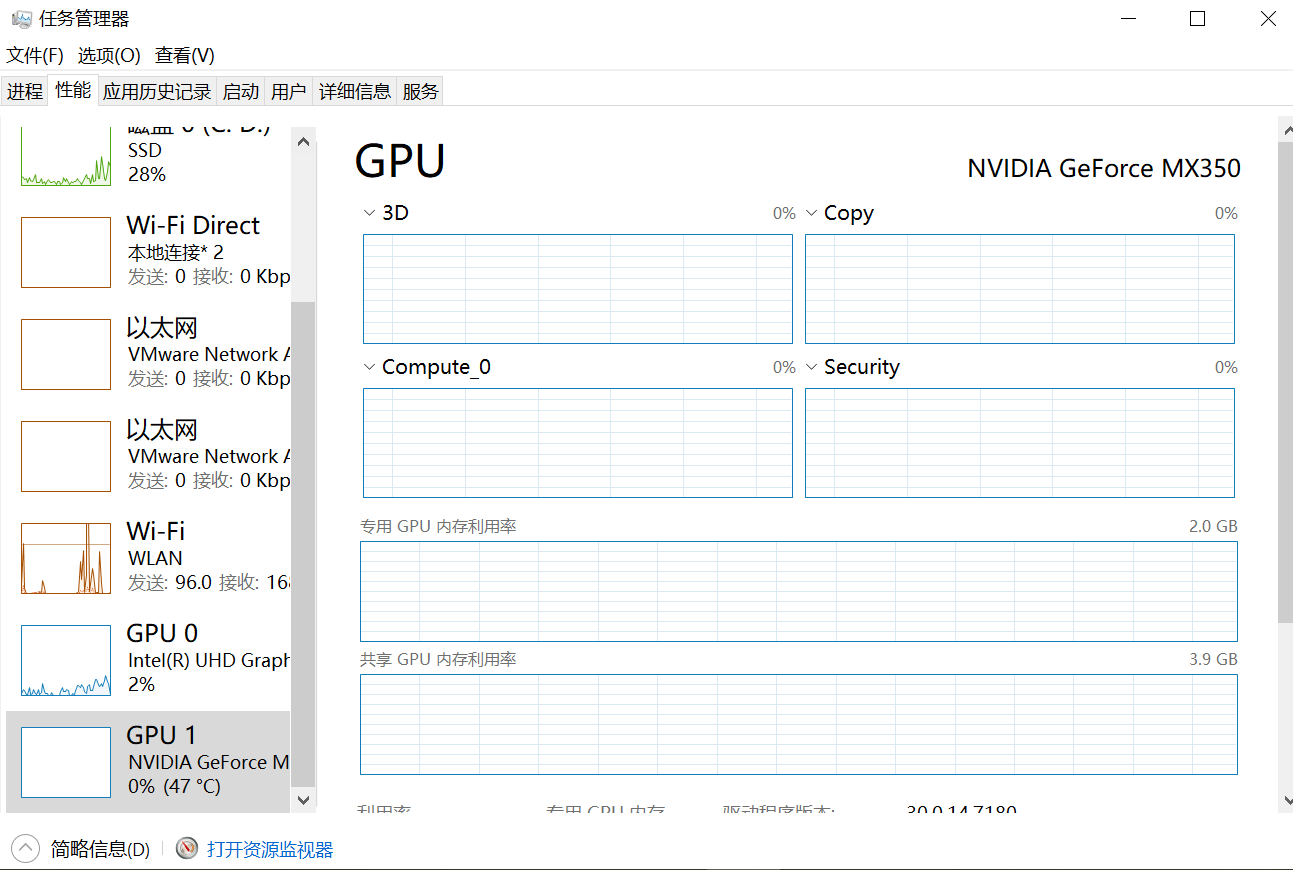
任务管理器查看是否有英伟达显卡
CUDA推荐使用9.2
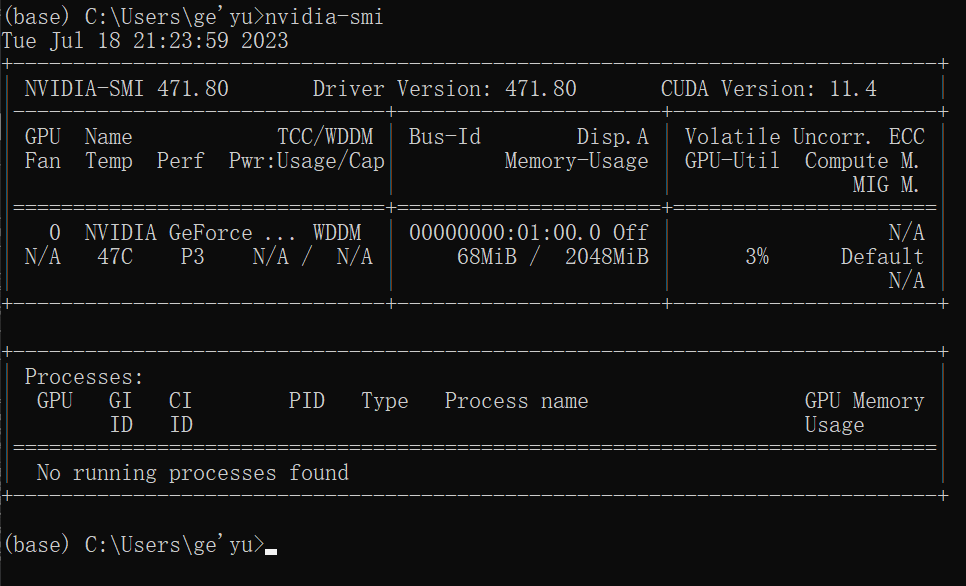
查看驱动版本
大于396.26可使用
pytorch环境下输入命令,安装9.2版本
1 | |

报错,因为下载速度太慢

清华源可以下载cpu版本:https://blog.csdn.net/zzq060143/article/details/88042075
如果找不到源,需要把命令中的 https 改成 http
下载gpu版本教程:https://www.bilibili.com/read/cv15186754
返回时False,因为装的是cpu版本,gpu版本才返回true。cpu版本学习阶段可以使用。

2 Python编辑器的选择
Pytorch安装
官网:https://www.jetbrains.com/pycharm/
下载Community版本
Pytorch 配置
create new project
需要自己配置解释器
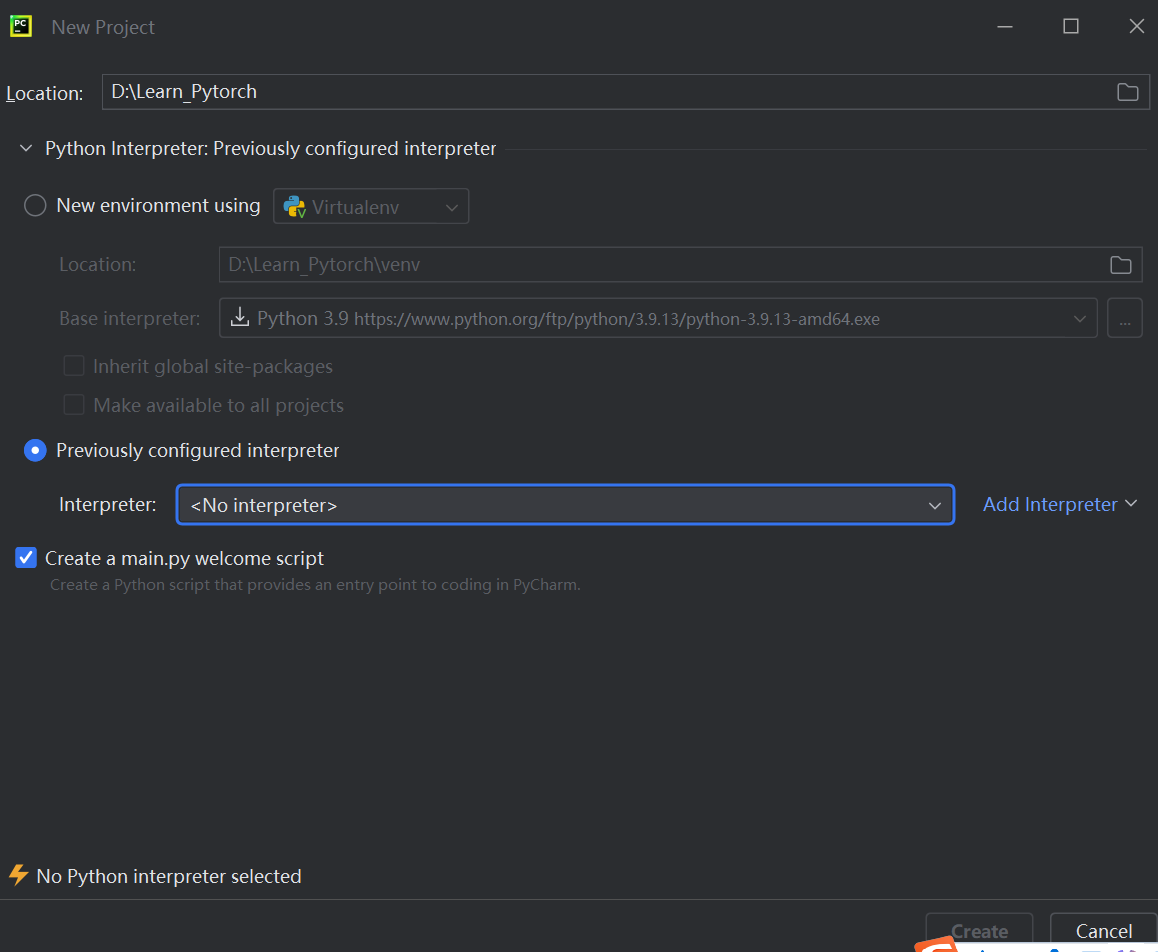
添加python.exe
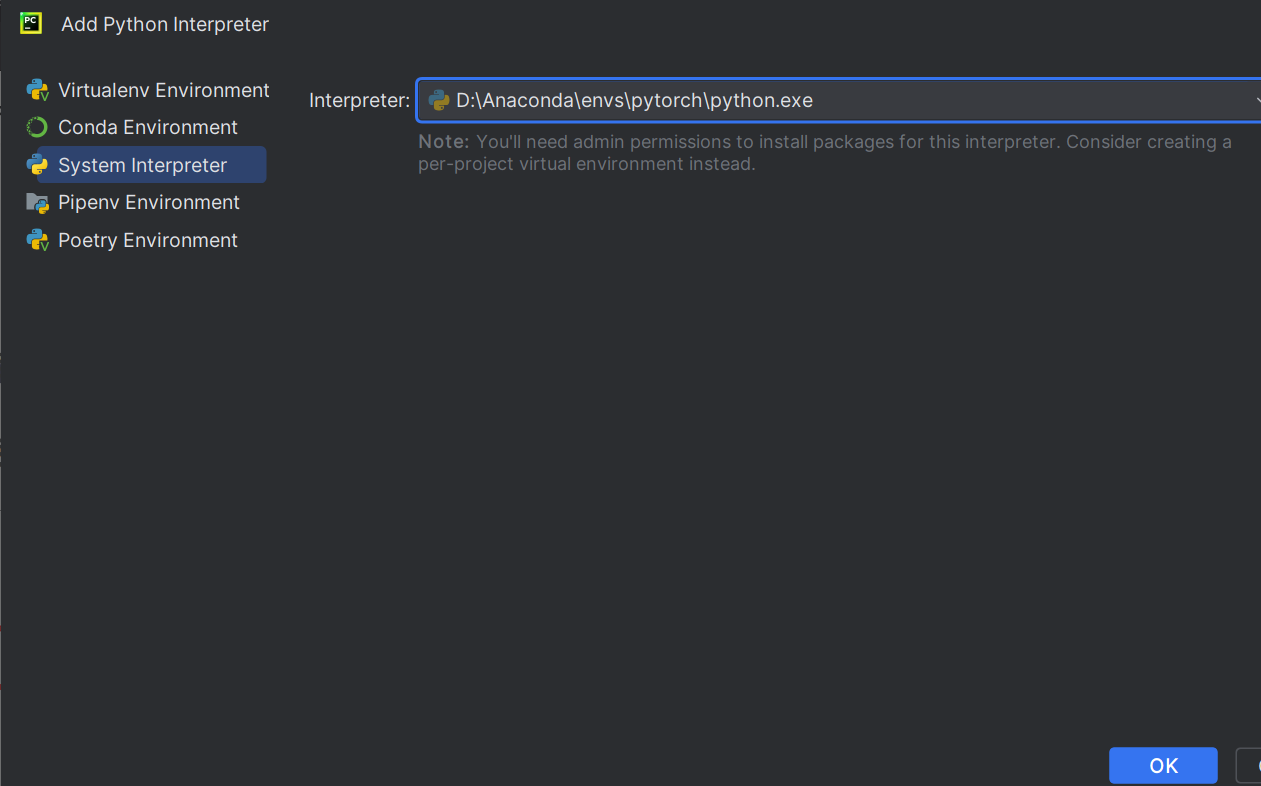
Conda Environment可能找不到python.exe,选择System Environment添加
https://blog.csdn.net/weixin_43537097/article/details/130931535
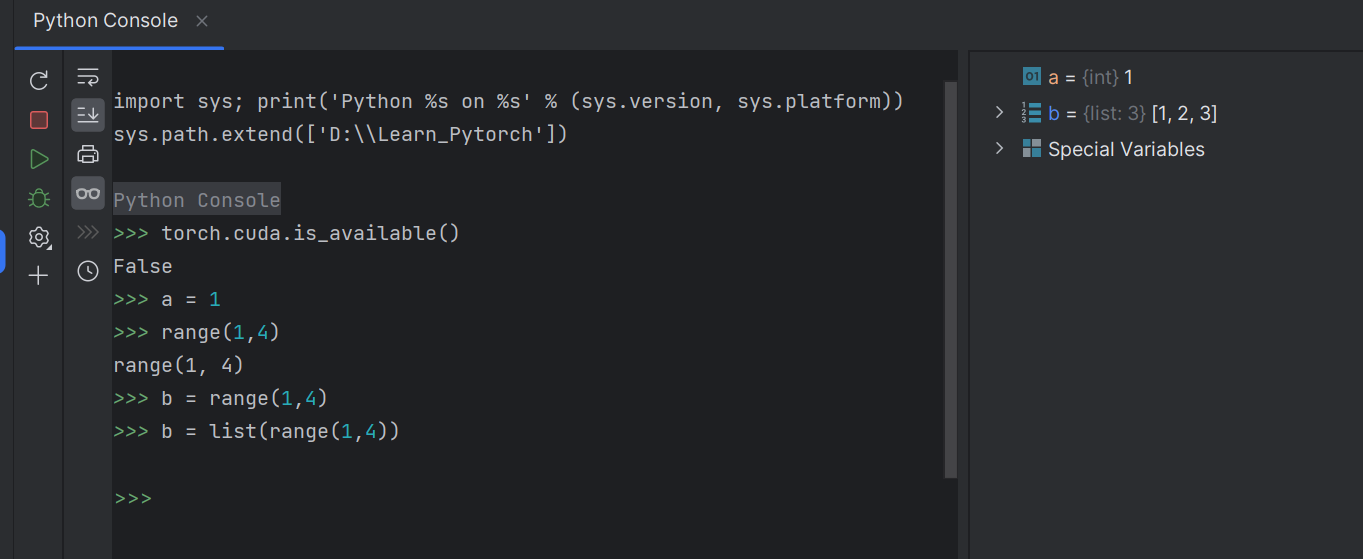
打开Python Consle
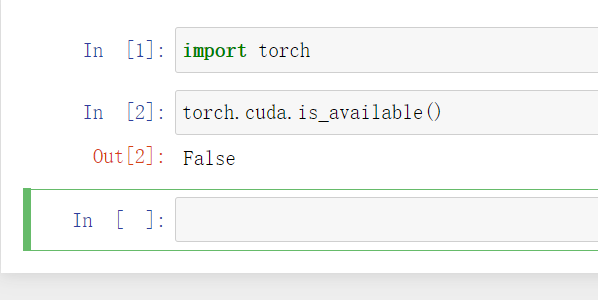
import torch
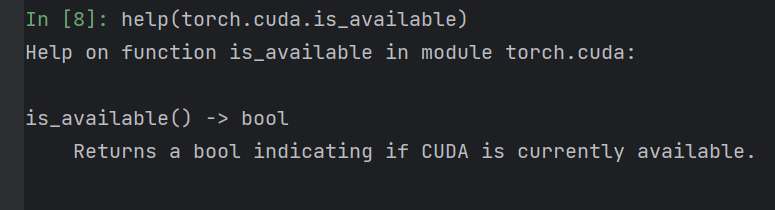
输入torch.cuda.is_available(),CPU版本返回false
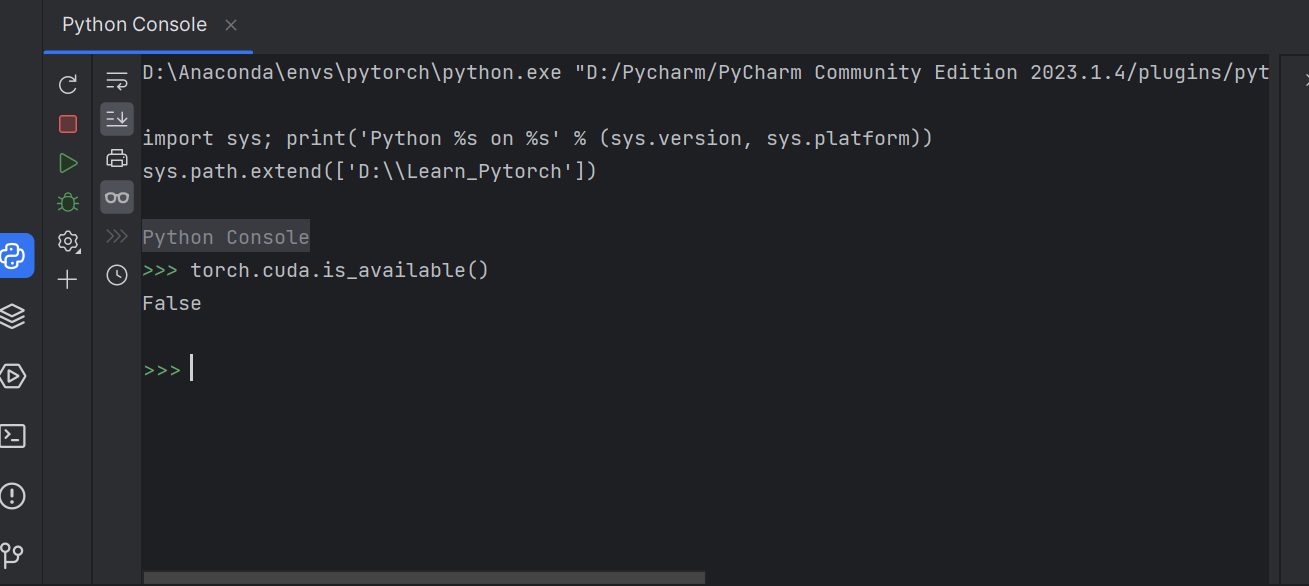
右侧工具栏可实时查看变量
Jupyter 安装
在Pytorch环境中安装Jupyter
在pytorch环境中安装一个包

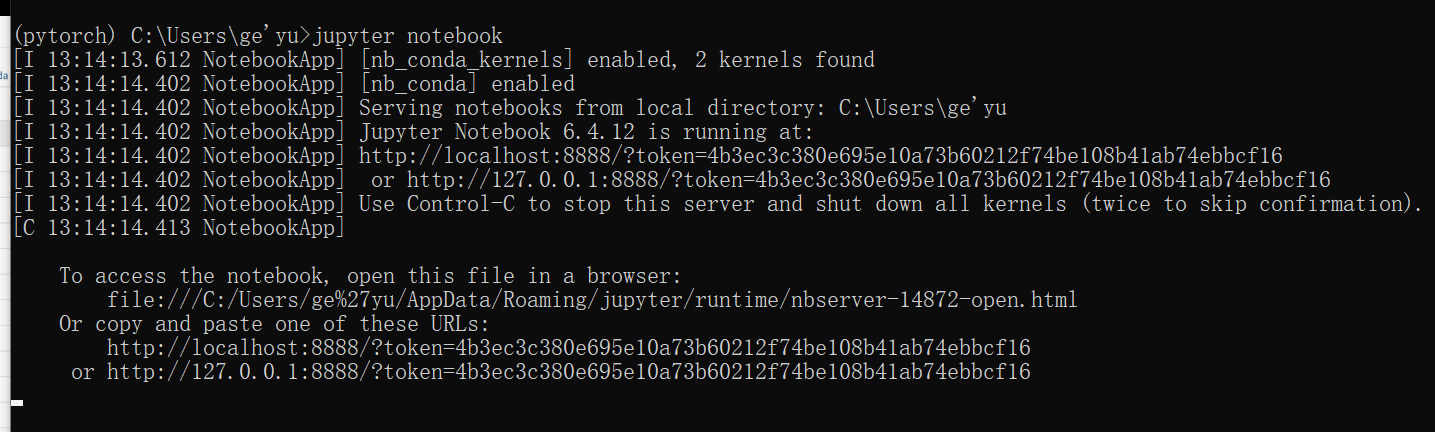
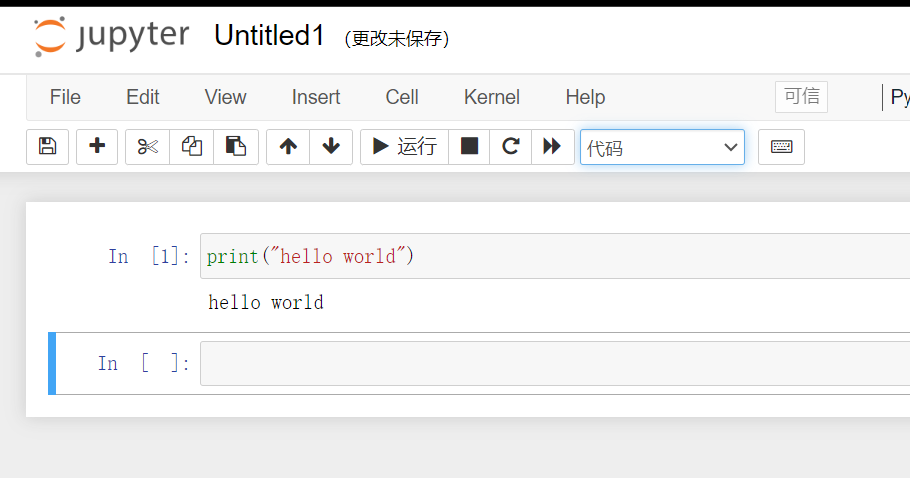
运行Jupyter
创建代码
shift + enter运行代码块
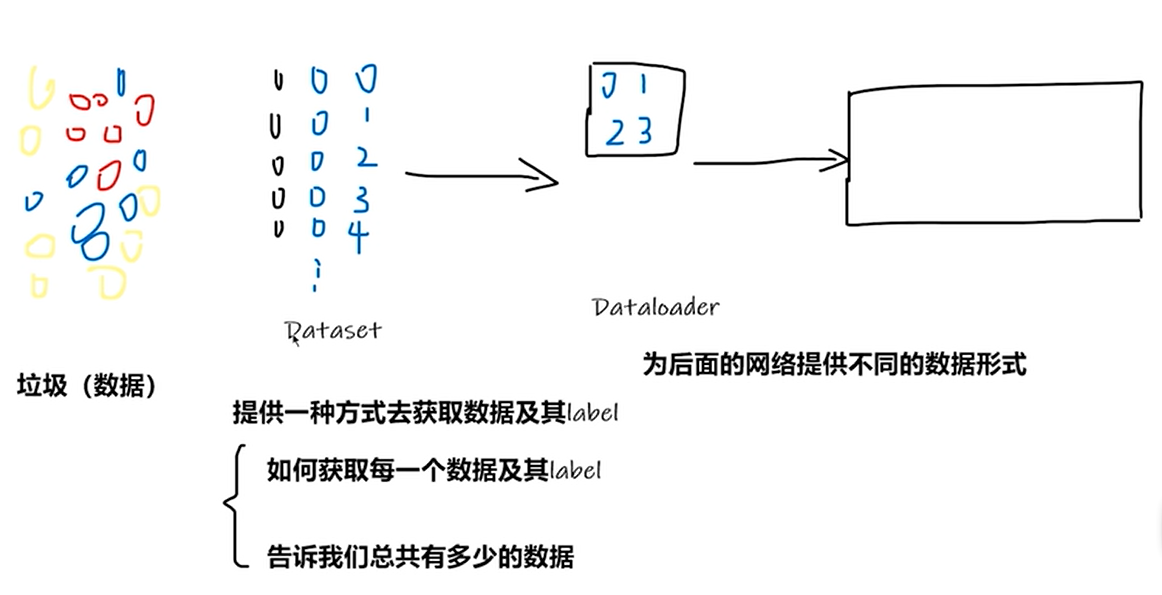
3 Pytorch学习中的两大法宝函数
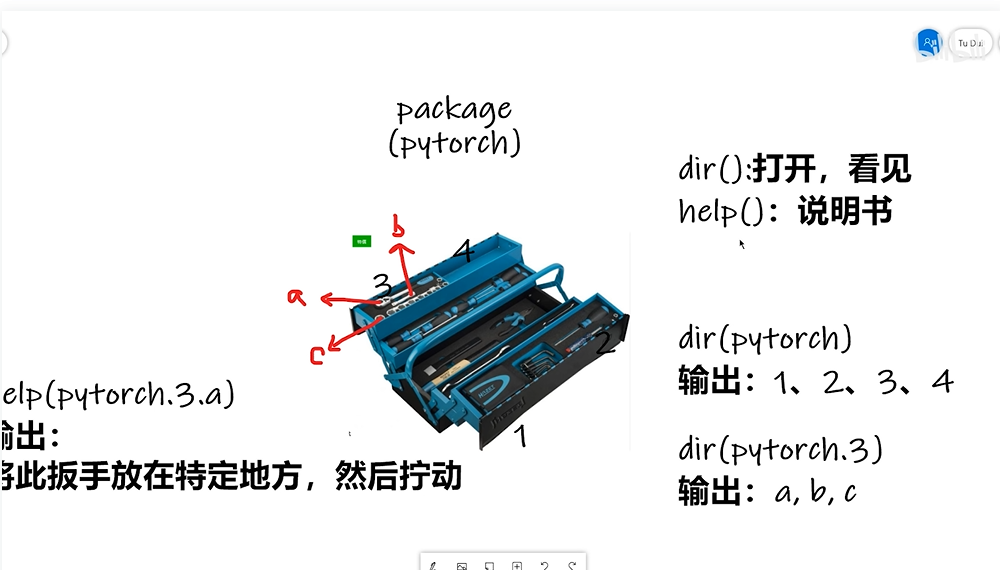
总结:
dir()函数,能让我们知道工具箱以及工具箱中的分隔区有什么东西。
help()函数,能让我们知道每个工具是如何使用的,工具的使用方法。
打开Pycharm,测试这两个工具函数
1 | |
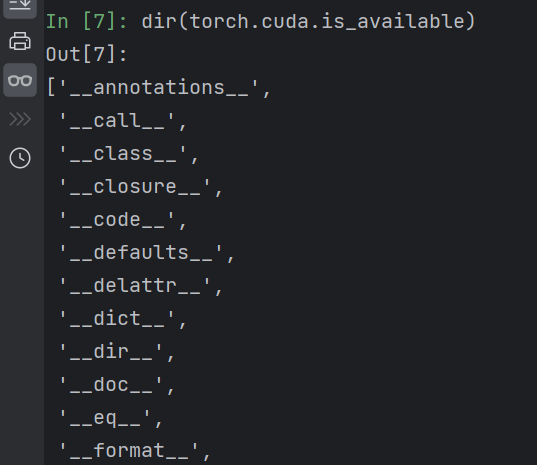
前后有双下划线,表明变量不能修改,说明是函数,不是分割区
dir和help里面函数后面的括号记得去掉
1 | |
4 Pycahrm及Jupyter使用对比
在Pycharm中新建项目
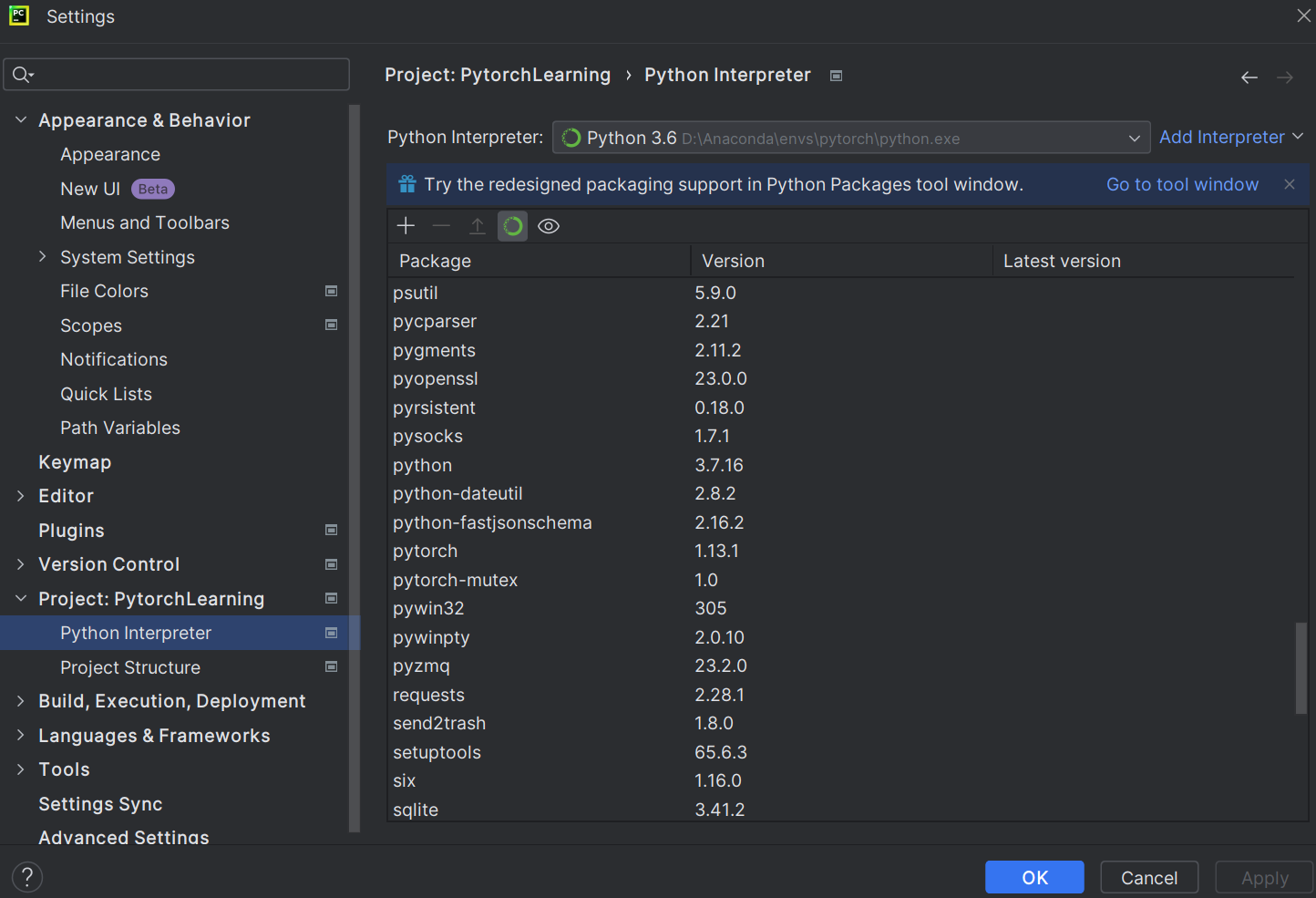
在File-Setting中可查看该项目是否有Pytorch环境
新建Python文件
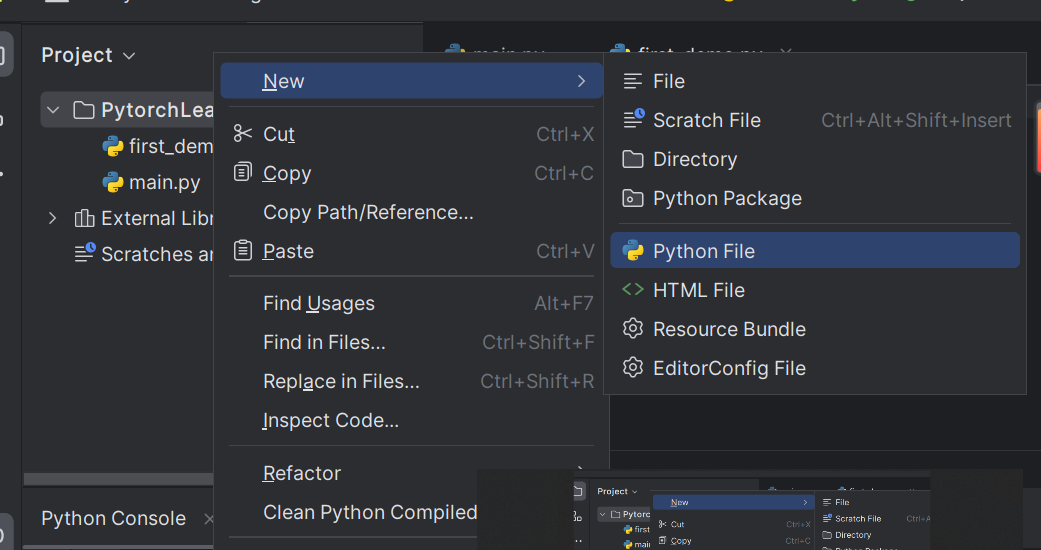
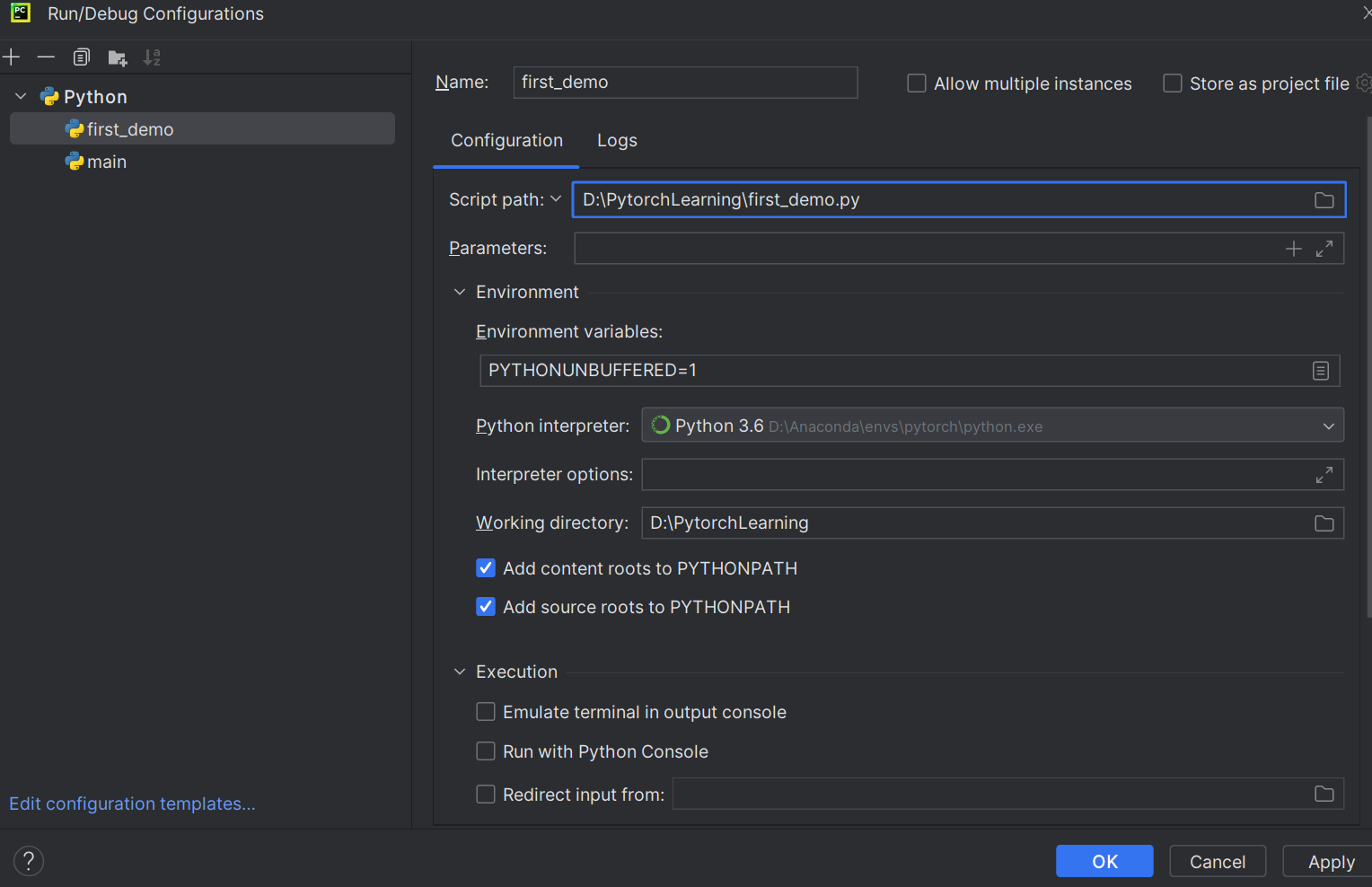
为Python文件设置Python解释器
运行成功
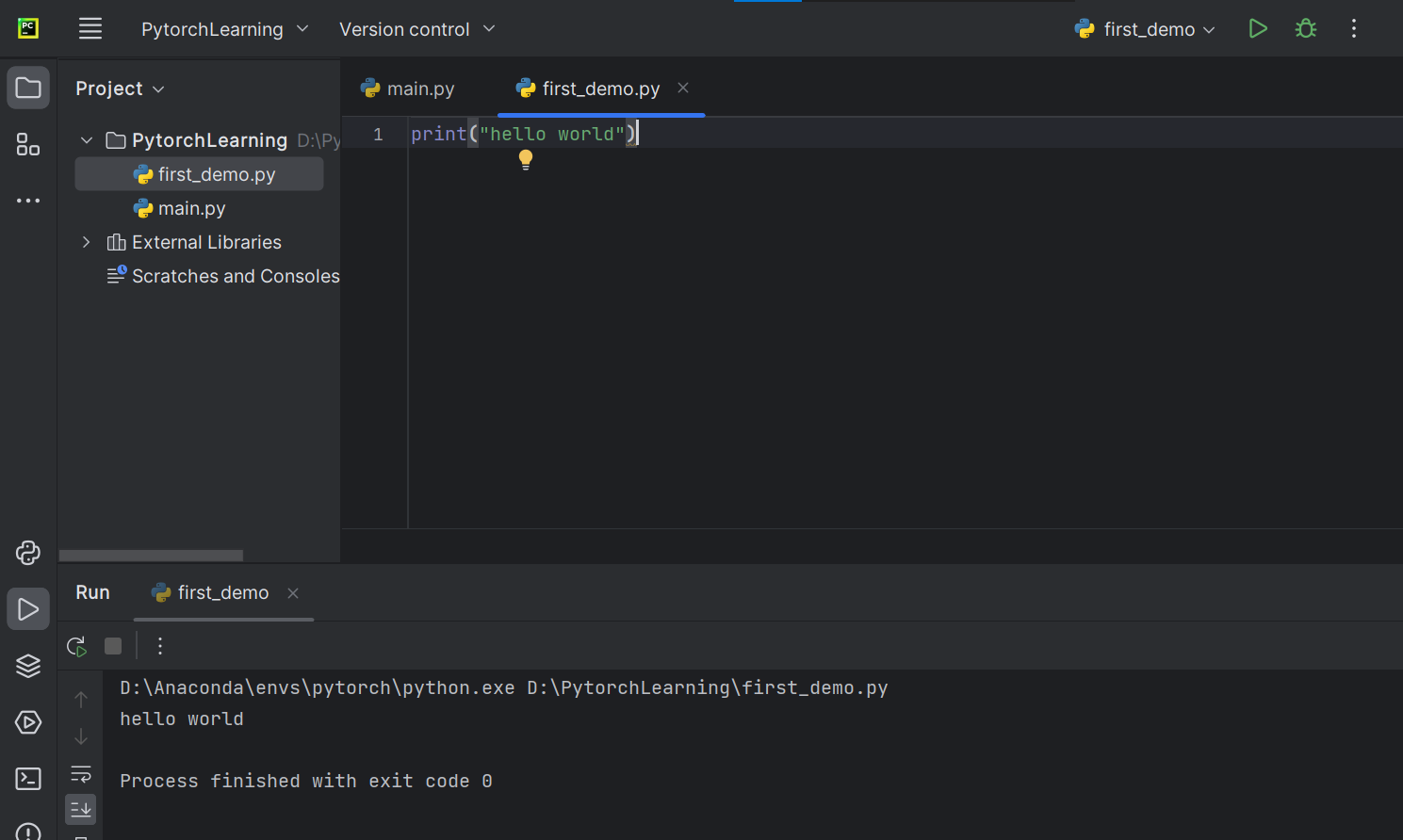
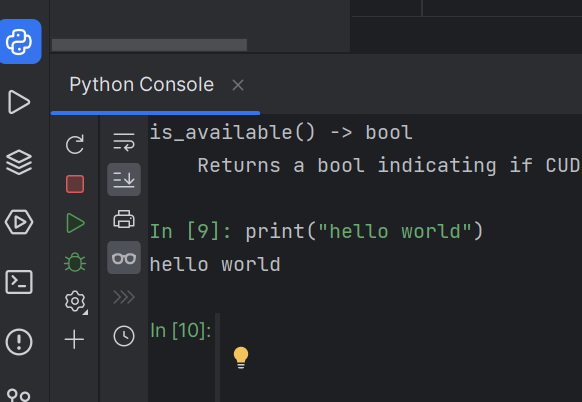
也可以直接在Python控制台输入语句,直接输出结果
Jupyter新建项目及使用
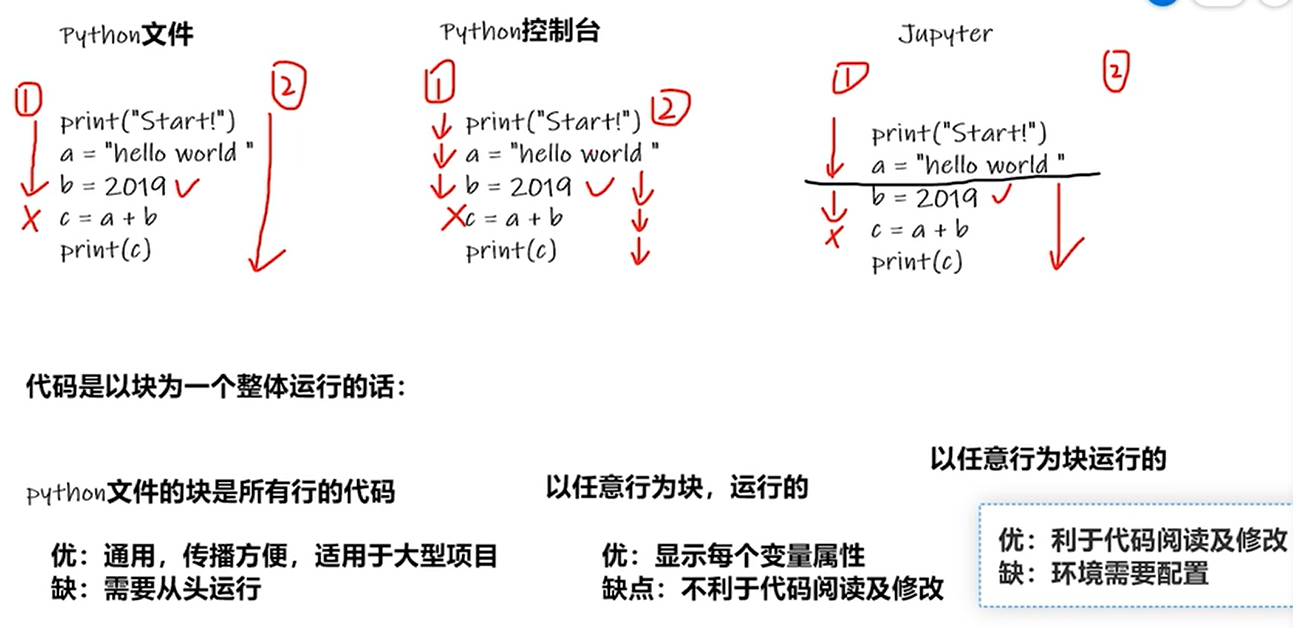
三种代码编辑方式对比
用三种方式运行同一段错误代码
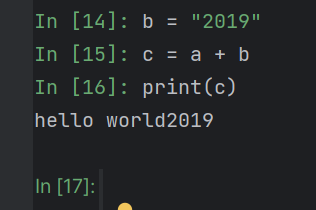
Python文件
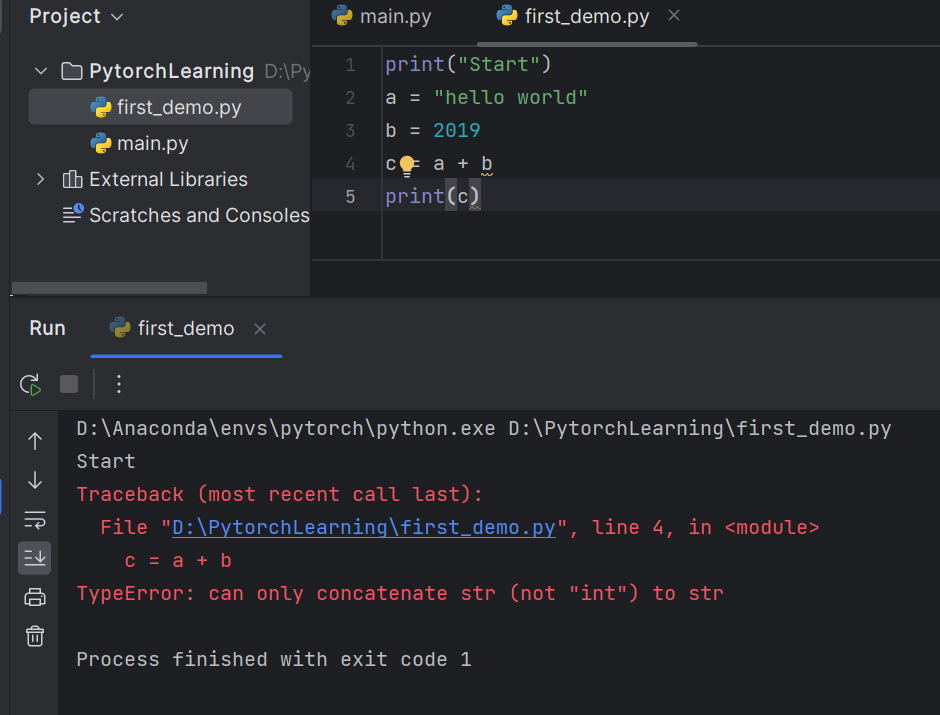
报错,字符串和整型相加不允许
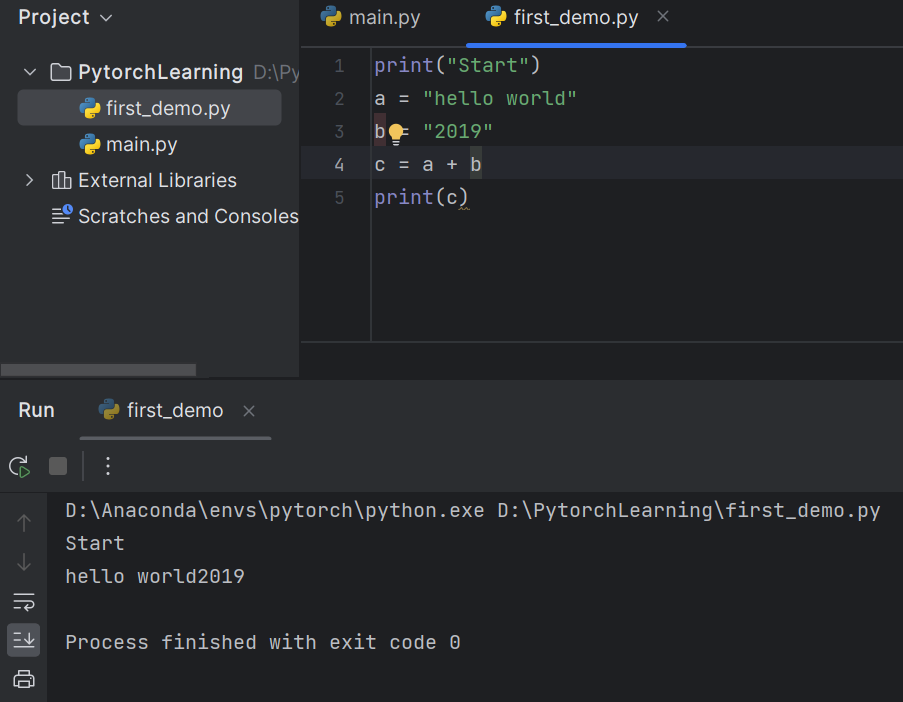
修改b后,运行成功
Python控制台
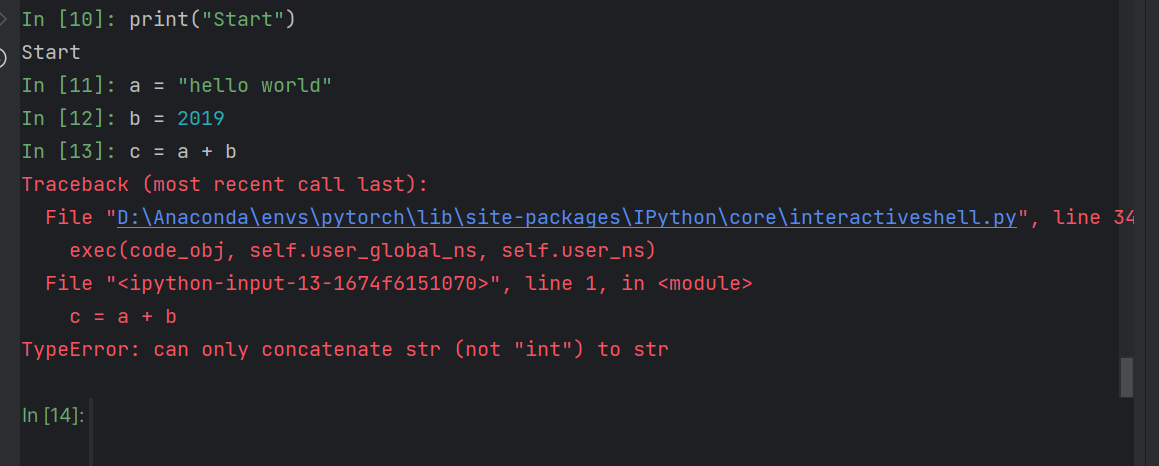
修改b后
如果发生错误,代码可读性下降
shift+enter可以以多行为一个块运行

Jupyter
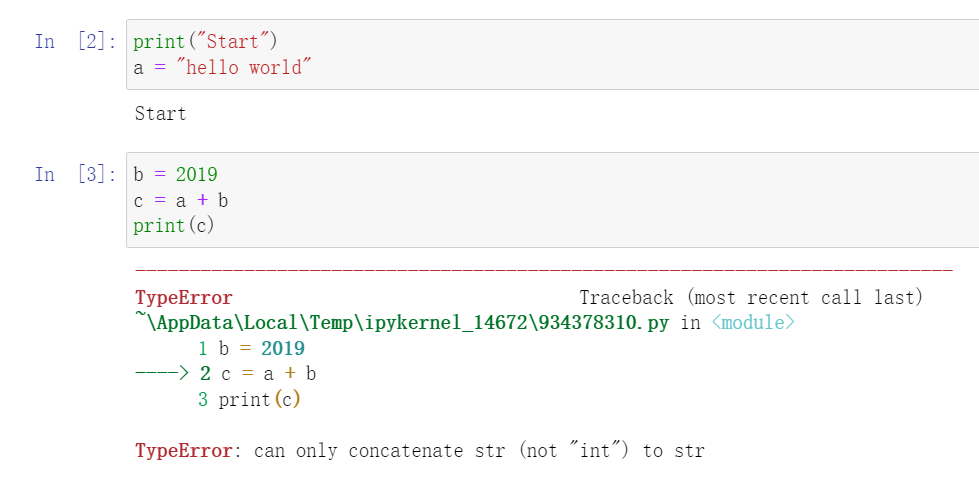
修改b后

·总结
5 Pytorch加载数据初认识
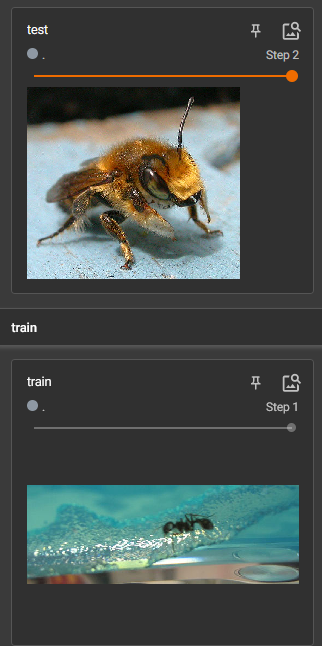
下载蚂蚁/蜜蜂数据集
创建read_data.py文件
1 | |
Jupyter中可查看Dateset内的函数
6 Dataset类代码实战
第一次打开终端报错解决:https://blog.csdn.net/qq_33405617/article/details/119894883
导入Image
1 | |
将 “蚂蚁/蜜蜂” 数据集复制到项目中
Python控制台中读取数据
1 | |
复制图片绝对路径,\改成\表示转义
1 | |

1 | |

1 | |
1 | |

获取图片名称及路径
控制台方式
1 | |
python文件方式
1 | |
数据集长度
1 | |
创建实例
1 | |
控制台运行
对象中包含init中的所有变量
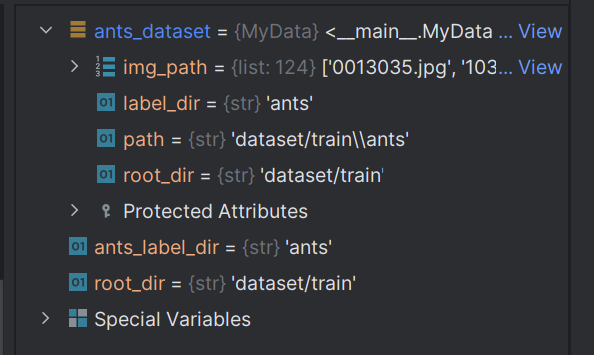
1 | |
同时有蚂蚁和蜜蜂数据集
1 | |
两个数据集集合
1 | |
txt标签方式
修改数据集文件名,添加标签文件夹
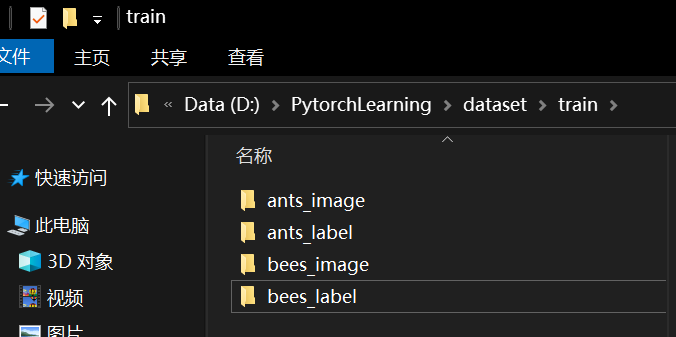
添加标签
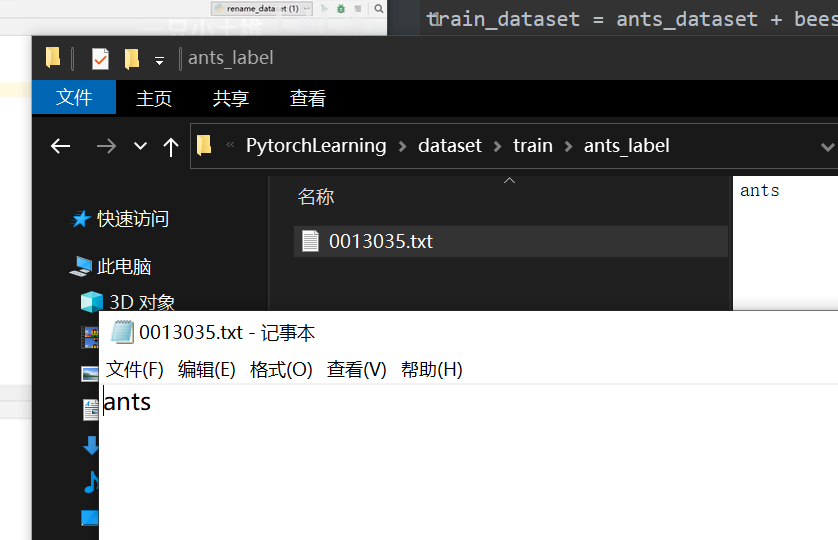
标签txt的名称与图片名称一致,txt内容为标签值
7 Tensorboard的使用(一)
打开Pycharm,设置环境
1 | |
add_scalar()方法

1 | |
安装TensorBoard
安装后再次运行,左侧多了一个logs文件

终端输入
1 | |
指定端口
1 | |
访问端口,显示图像
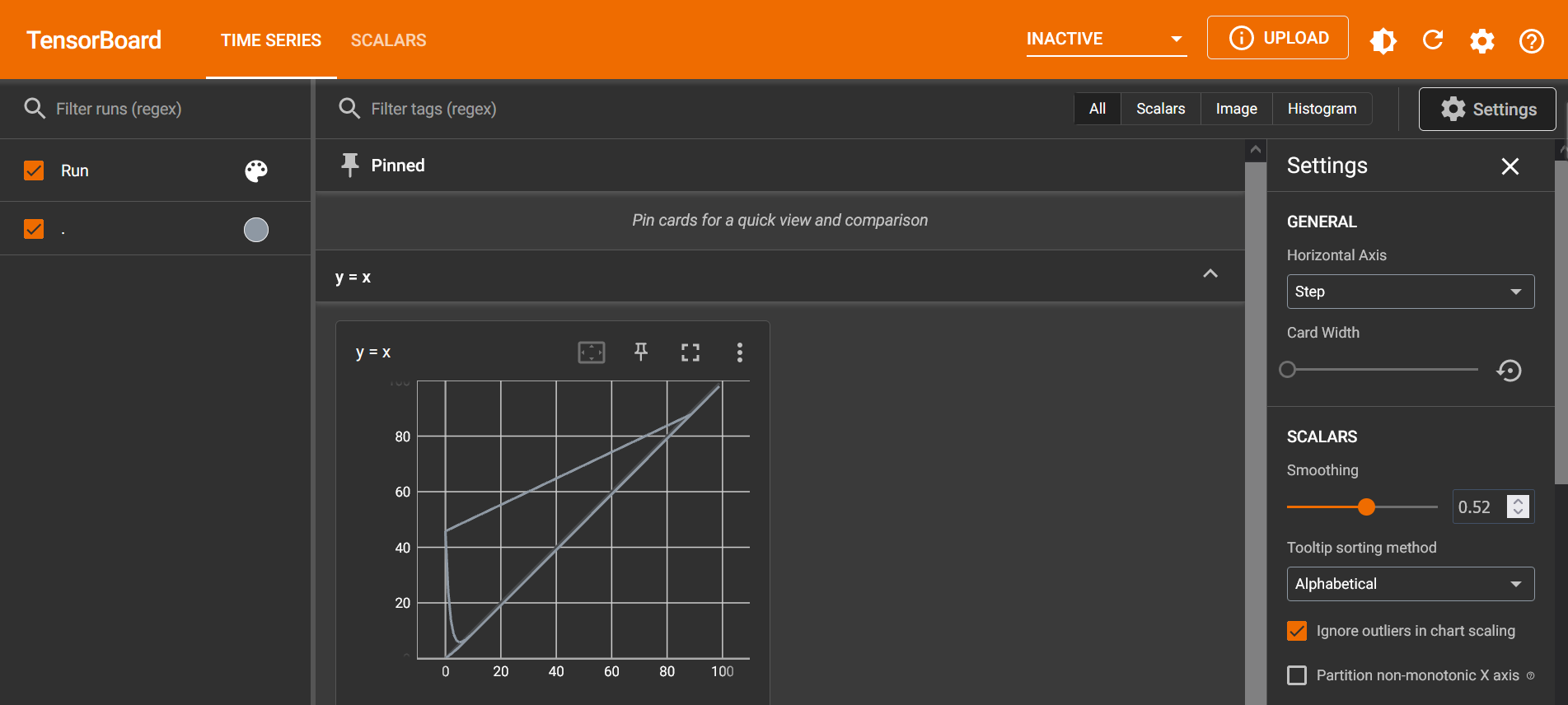
绘制y=2x
1 | |
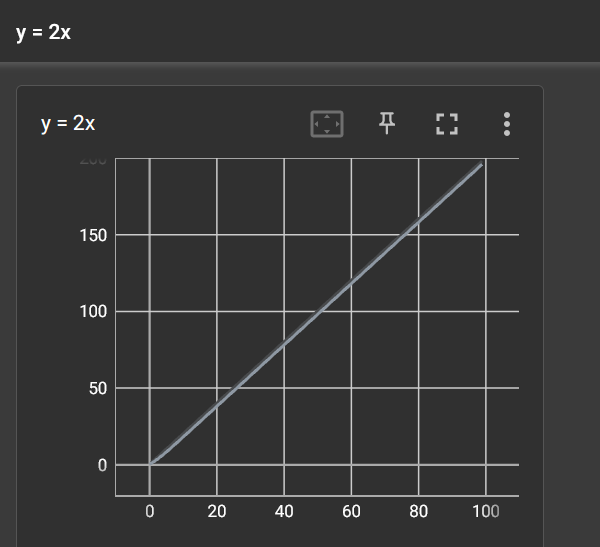
如果不改变add_scalar()函数的标题只改变参数
1 | |
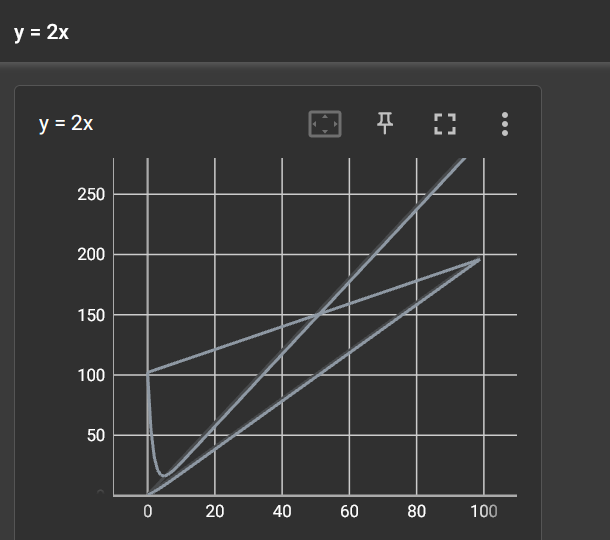

向writer中写入新的事件,同时也记录了上一个事件
解决方法:
一、删除logs下的文件,重新启动程序
二、创建子文件夹,也就是说创建新的SummaryWriter(“新文件夹”)
8 TensorBoard的使用(二)add image()的使用(常用来观察训练结果)
控制台输入
1 | |
利用numpy.array(),对PIL图片进行转换
NumPy型图片是指使用NumPy库表示和处理的图像。NumPy是一个广泛使用的Python库,用于科学计算和数据处理。它提供了一个多维数组对象(ndarray),可以用于存储和操作大量的数值数据。在图像处理领域中,NumPy数组通常用来表示图像的像素值。
NumPy数组可以是一维的(灰度图像)或二维的(彩色图像)。对于彩色图像,通常使用三维的NumPy数组表示,其中第一个维度表示图像的行数,第二个维度表示图像的列数,第三个维度表示图像的通道数(例如,红、绿、蓝通道)
控制台
1 | |
文件内
1 | |
从PIL到numpy, 需要在add image()中指定shape中每一个数字/维表示的含义。
打开端口,显示图像
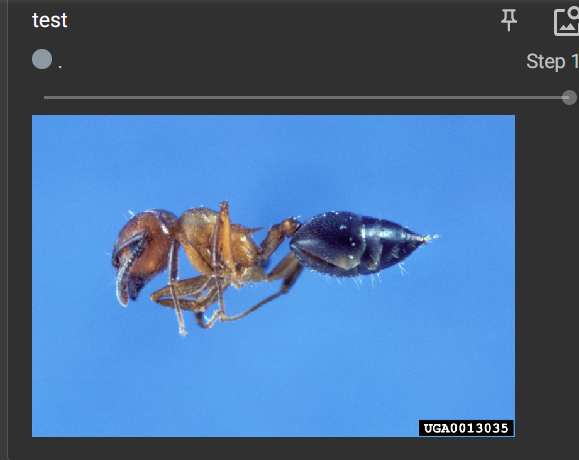
添加蜜蜂图片,修改步长为2
1 | |

更换标题
1 | |
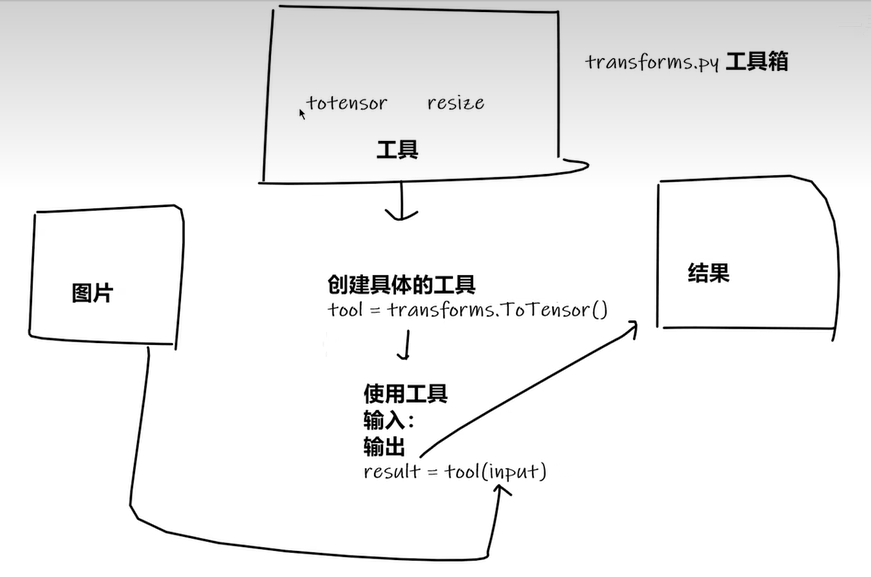
9 Transforms 的使用(一)
transforms结构及用法
ctrl+p可提示函数需要什么参数
1 | |
10Transforms的使用(二)
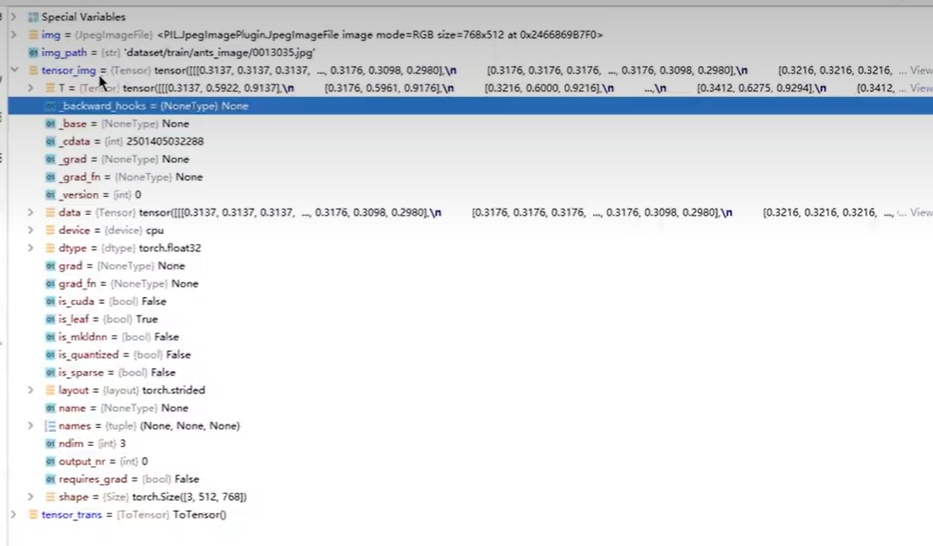
Tensor包括深度学习需要的参数
下载Opencv
终端输入
1 | |
控制台
1 | |
利用Tensor_img显示图片
1 | |
终端输入
1 | |
打开端口,显示图片
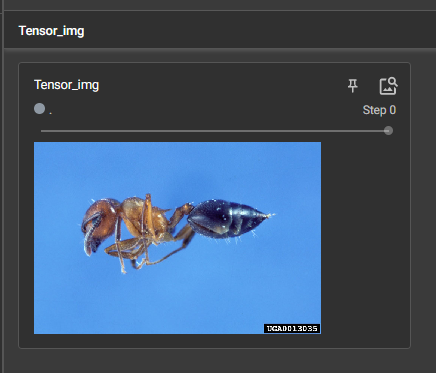
11 常见的Transforms(一)
Pytorch中call()的用法
1 | |
ToTensor的使用
1 | |
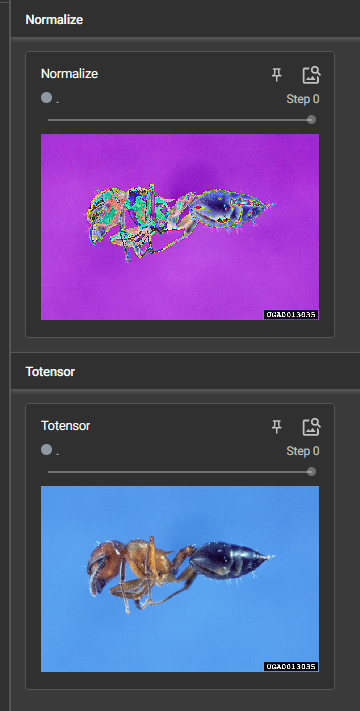
Normalize() 归一化 的使用

mean是均值,std是标准差
1 | |
输出归一化结果
1 | |
12 常见的Transforms(二)
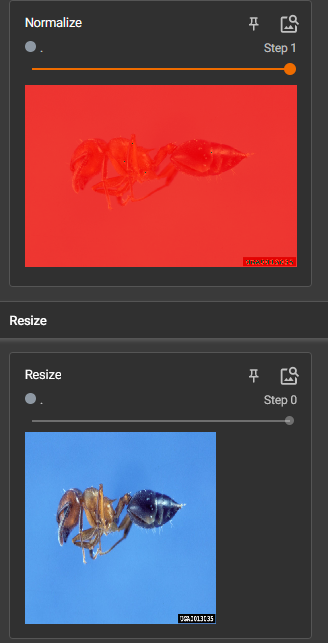
Resize()的使用
1 | |
将PIL类型的img_resize转为tensor类型
1 | |
图片大小改变
Compose()的使用
将不同的操作组合起来,按顺序执行。前一步的输出是下一步的输入,要对应。
Compose()中的参数需要是一个列表。Python中,列表的表示形式为[数据1,数据2,…]。在Composel中,数据需要是transforms类型,所以得到,Compose([transforms参数1,transforms参数2,…])
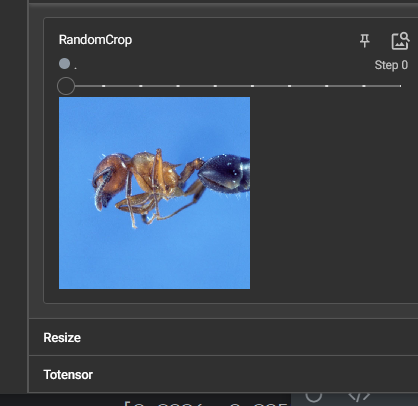
RandomCrop()随机裁剪的用法
1 | |
总结使用方法
- 关注输入和输出类型
- 多看官方文档
- 关注方法需要什么参数
- 不知道返回值的时候
- print()
- print(type())
- debug
13 torchvision中的数据集使用
下载训练集和测试集
1 | |
可以用迅雷加快下载速度
1 | |
classes内表示每种target对应哪种类别
1 | |
添加Transform参数
1 | |
14 DataLoader的使用
测试数据集中第一张图片及target
1 | |

理解batch_size
1 | |
更改batch_size=64
1 | |
drop_last设置为false,所以不会丢掉数量小于batch_seze的组。
理解shuffle
添加epoch
1 | |
shuffle为false时两轮图片加载中随机选取结果相同
 15 神经网络的基本骨架-nn.Module的使用
15 神经网络的基本骨架-nn.Module的使用

自定义神经网络
重写方法

1 | |
16 卷积操作
卷积核移动,每个位置,卷积核的每一小块与输入图像重叠部分每一小块的相乘,所有乘积相加即为输出的一个小块
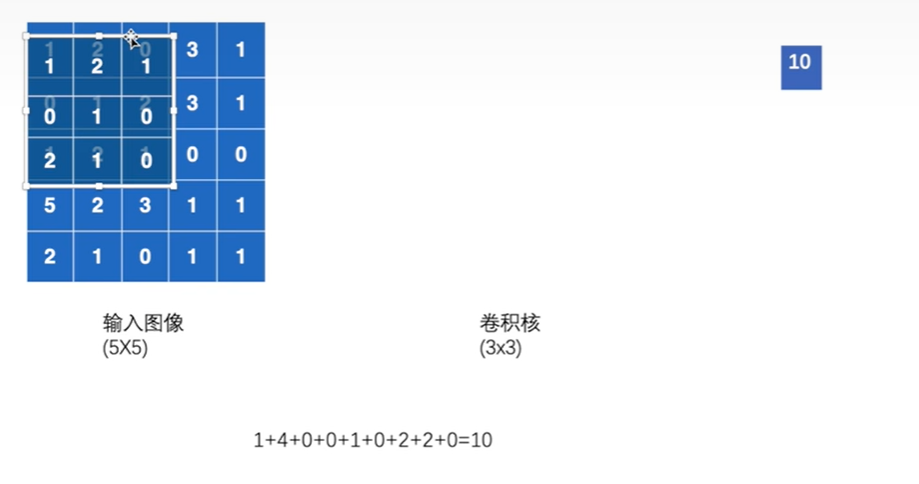
Stride为卷积核每次移动的步数
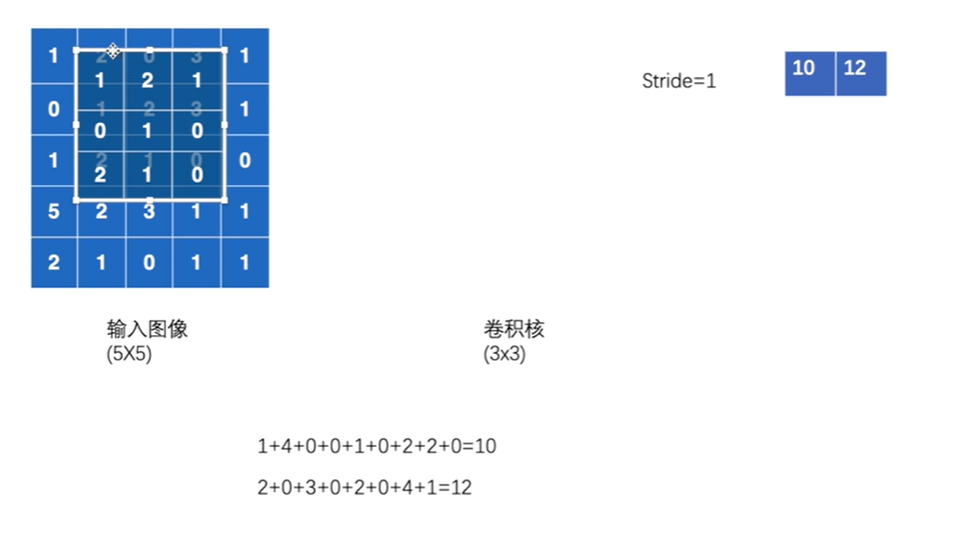
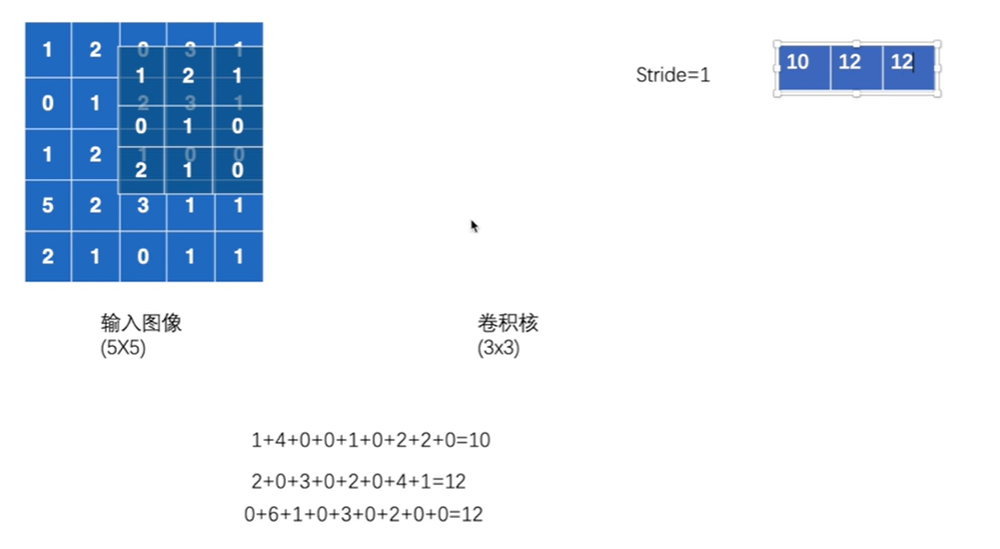
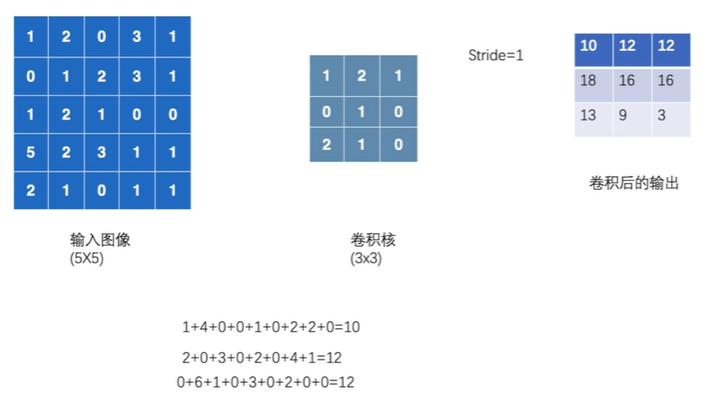
编写程序
1 | |
使用reshape()
1 | |
实现卷积操作
1 | |
改变stride 步幅
1 | |
Padding 填充
图像周围填充0
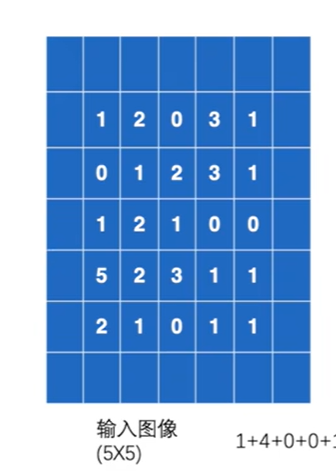
1 | |
17 神经网络-卷积层
In_channel输入通道和Out_channel输出通道
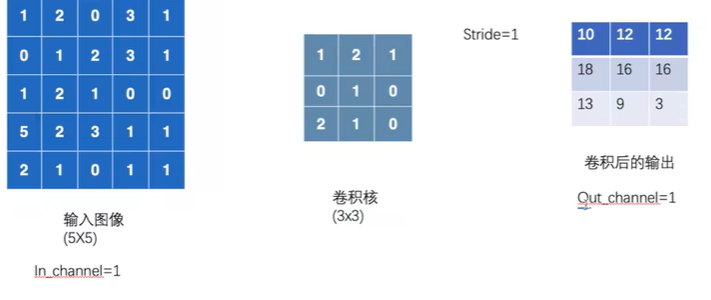
out_channel为2时
卷积操作完成后输出的 out_channels,取决于卷积核的数量。
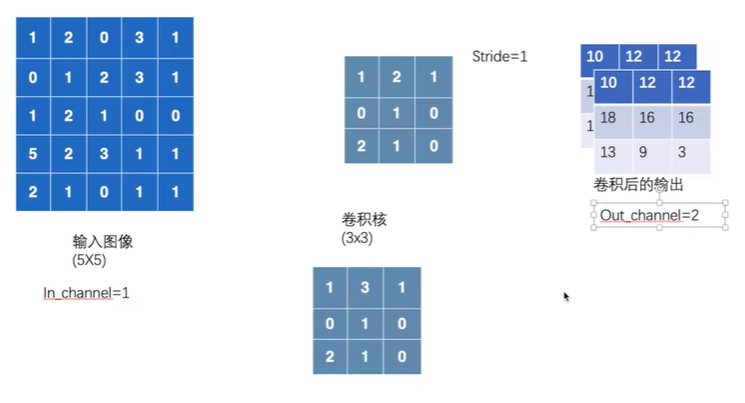
编写代码验证
1 | |
1 | |
output为6个channel无法用writer显示,用reshape变为3个channel
1 | |
18 最大池的使用
ceil mode和floor mode
ceil mode是向上取整,floor mode是向下取整
具体到池化操作,ceil mode指如果池化核覆盖范围内有空缺,还是保留空缺继续池化;floor mode就会将空缺舍弃,不对其进行池化。
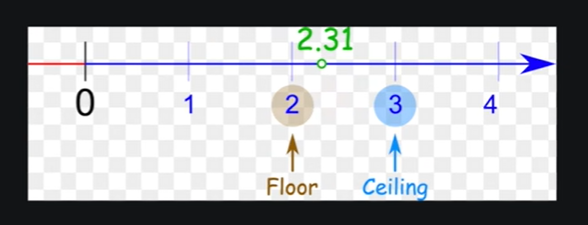
每次找出被池化核覆盖的范围内的最大值输出
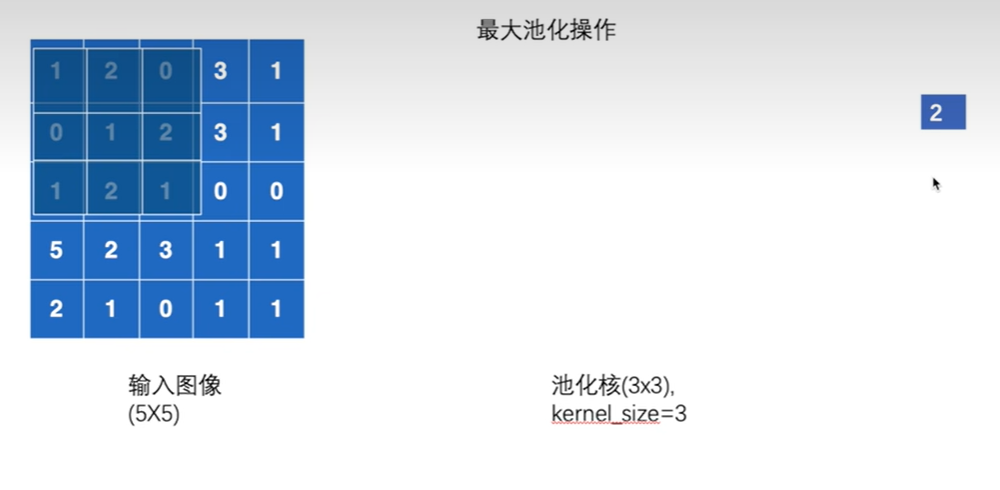
步幅为kernel_size的大小,3
Ceil mode


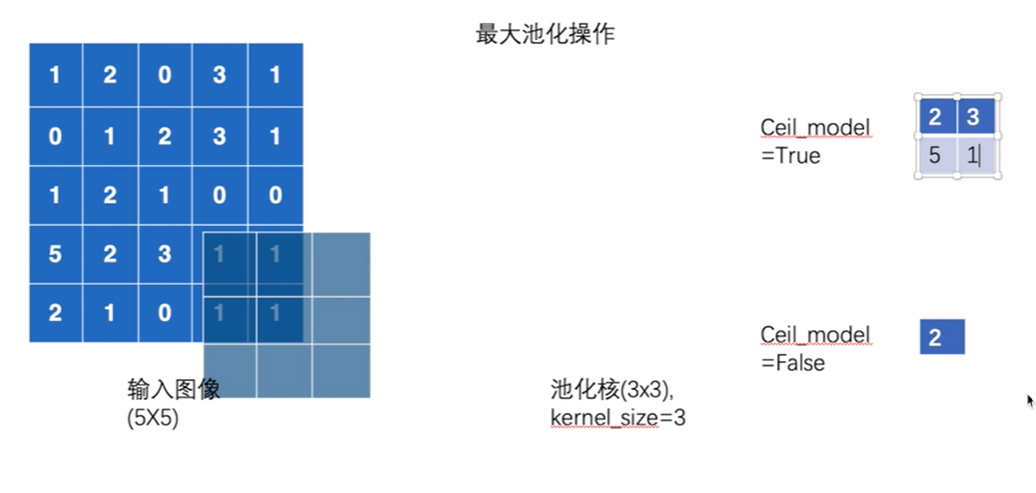
默认情况ceil mode为false,即不保留
代码演示
1 | |
Ceil mode为False
1 | |
最大池化的作用
保留数据特征,减小数据量
1 | |
19 非线性激活
以ReLU为例
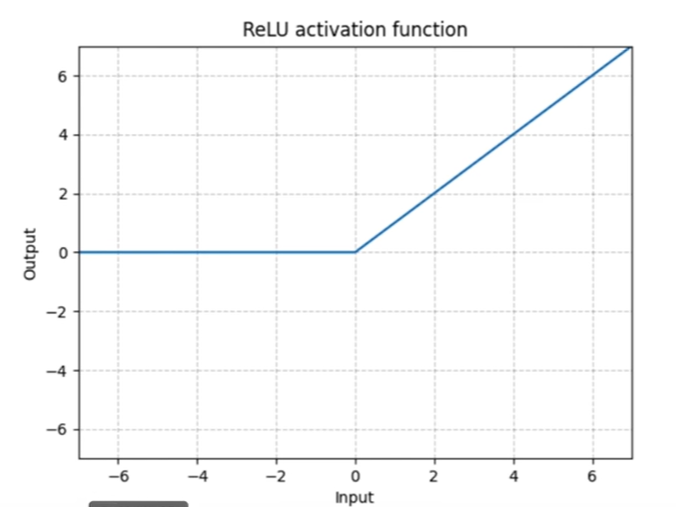
参数inPlace
表示是否对原来变量进行变换,默认是False

1 | |
Sigmoid函数
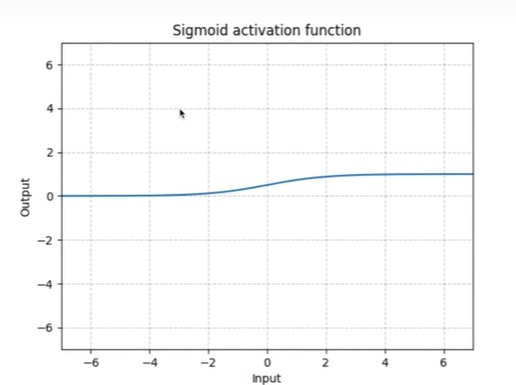
1 | |
20 线性层及其它层介绍
线性层
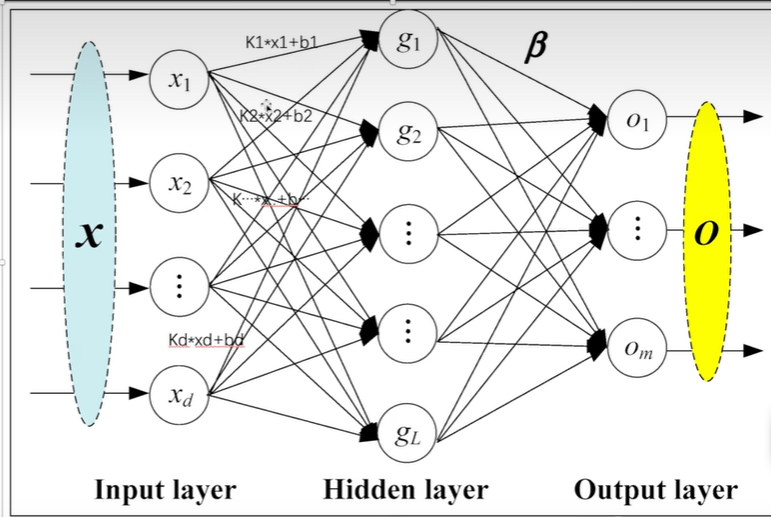
5×5经过reshape变为1×25,再经过线性层变为1×3
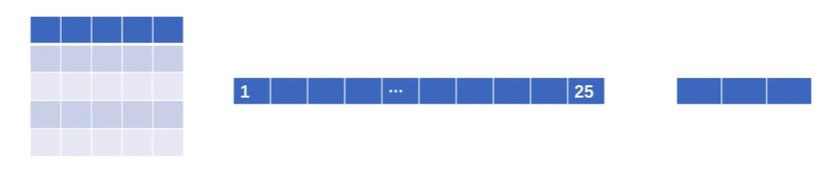
1 | |
Flatten()函数
可以把输入展成一行,变为一维向量

1 | |
21 搭建小实战和Sequential的使用
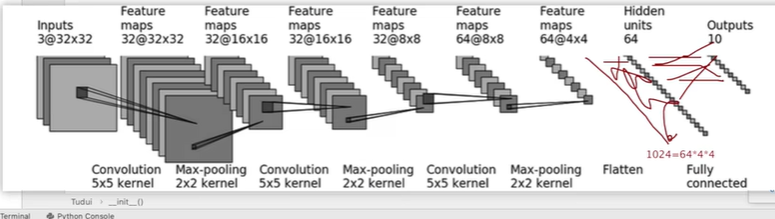
卷积的padding和stride可以用公式计算

padding为2,stride为1

创建网络
1 | |
检查网络正确性
1 | |
Sequential使用
代码更简洁
1 | |
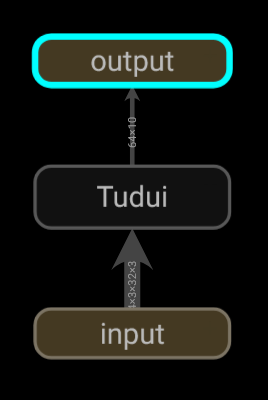
add_graph()显示训练过程
1 | |
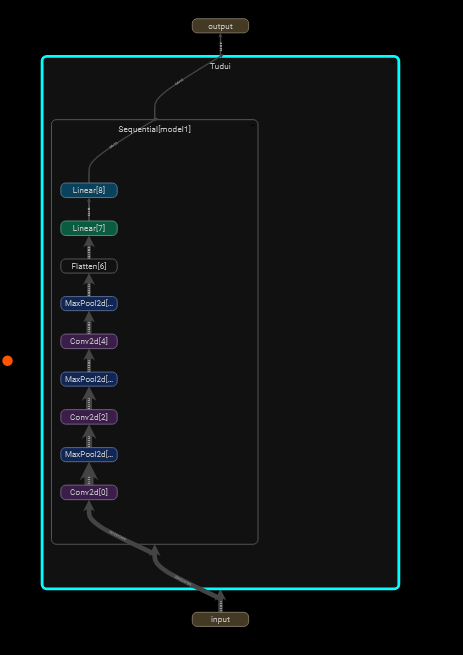
双击查看细节
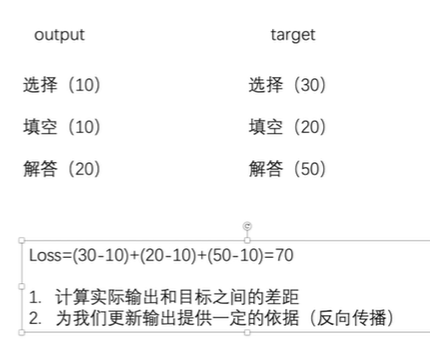
22 损失函数与反向传播

L1loss 函数


1 | |
改变reduction
1 | |
MSELOSS 平方差
1 | |

交叉熵
分类问题。下图的log应该是ln
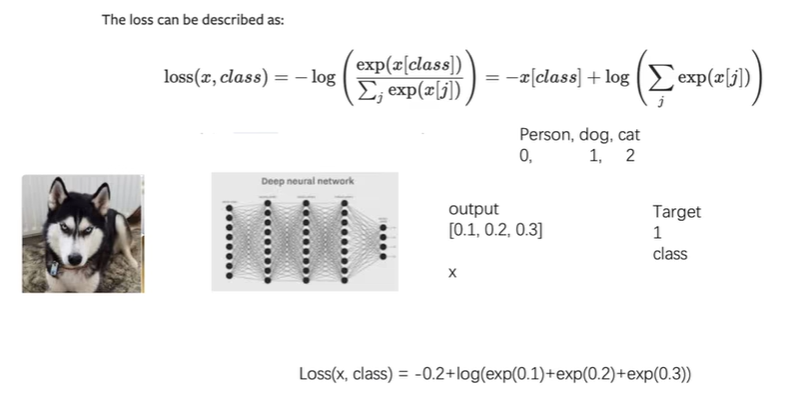
1 | |
查看输出和target
1 | |
添加交叉熵
1 | |
梯度下降法
1 | |
23 优化器(一)
1 | |
24 现有网络模型的使用及修改
VGG16
最后out_feature为1000,表明1000个分类
1 | |
给vgg16多添加一个线性层,实现10个分类
1 | |
将线性层加到classifier中
1 | |
1 | |
25 网络模型的保存与读取
保存vgg16
1 | |
加载模型
1 | |
保存方式2
1 | |
恢复成网络模型
新建网路模型结构
1 | |
方式1陷阱
保存模型
1 | |
加载时报错
1 | |
需要将模型的定义放在需要加载的文件
1 | |
26 完整的模型训练
Argmax
输入两张图片,通过outputs得到预测类别Preds
将Preds与Inputs target比较。
[false, true].sum()=1,false看成0,true看成1

1 | |


1 | |
完整代码
model.py
1 | |
训练和测试代码
1 | |
注意点
train()和eval()
1 | |
27 利用GPU训练(一)

1 | |
Goole Colaboratory
打开GPU
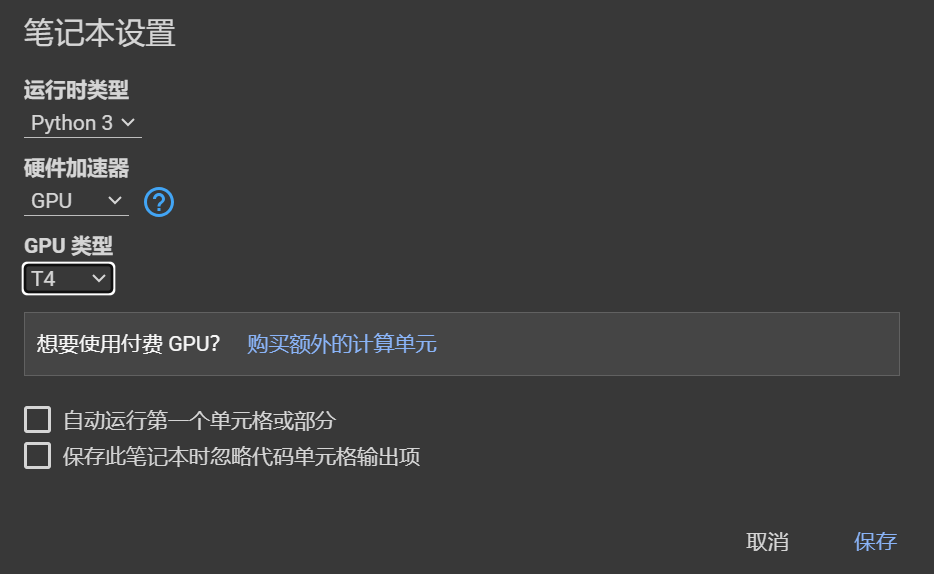
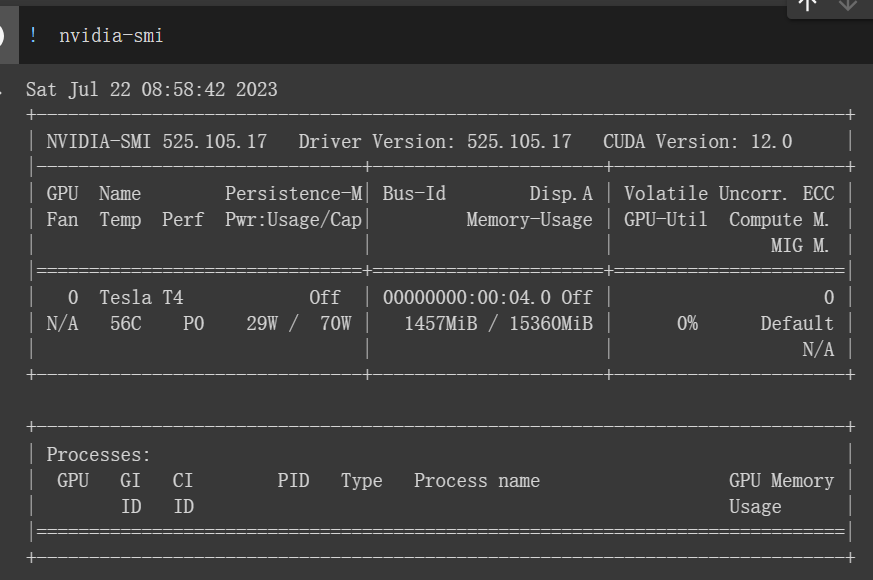
代码前加!表示不用python语法,用终端语法
28 利用GPU训练(二)
1 | |
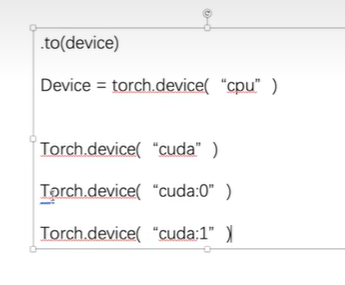
device写法
1 | |
29 完整模型验证
1 | |
30 阅读开源项目
1 | |

requered=True表明一定需要这个参数
可以把其改成default,就可以在pycharm中右键运行
1 | |