1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
| import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
import time
train_data = torchvision.datasets.CIFAR10(root = "./data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root = "./data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
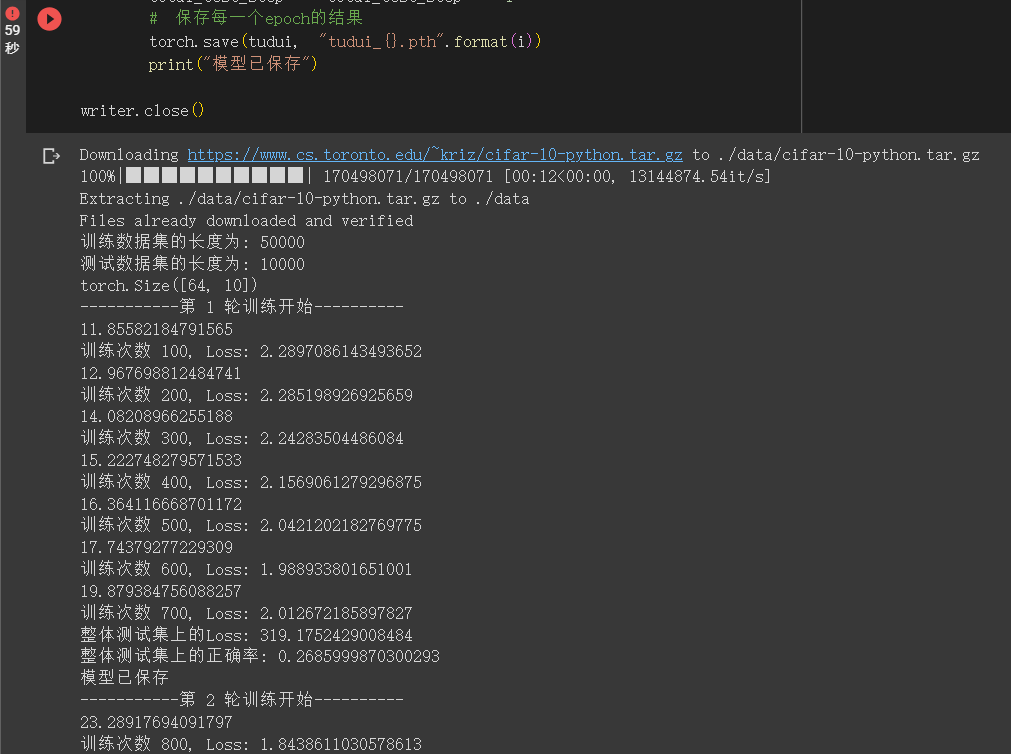
print("训练数据集的长度为: {}".format(train_data_size))
print("测试数据集的长度为: {}".format(test_data_size))
train_dataloader = DataLoader(train_data, 64)
test_dataloader = DataLoader(test_data, 64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
tudui = Tudui()
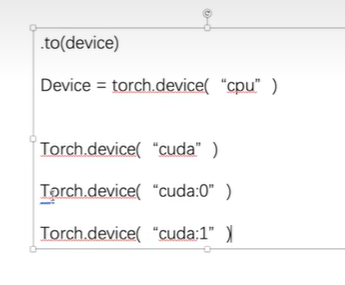
if torch.cuda.is_available():
tudui = tudui.cuda()
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter("logs_train")
start_time = time.time()
for i in range(epoch):
print("-----------第 {} 轮训练开始----------".format(i + 1))
tudui.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
output = tudui(imgs)
loss = loss_fn(output, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数 {}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
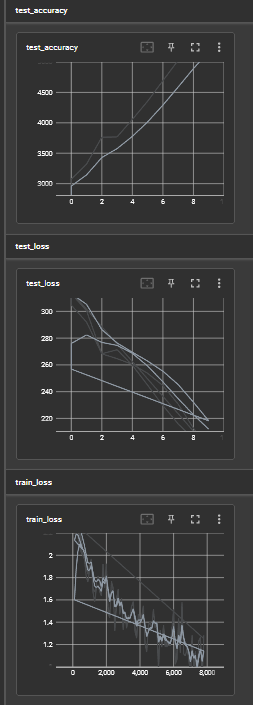
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
'''
-----------第 1 轮训练开始----------
6.235116958618164
训练次数 100, Loss: 2.292055368423462
'''
|